性能分析计算#
使用 Perfetto 查看程序跟踪#
我们可以使用 JAX 性能分析器生成 JAX 程序的跟踪,这些跟踪可以使用 Perfetto 可视化工具进行可视化。目前,此方法会阻塞程序,直到单击链接并加载 Perfetto UI 跟踪。如果您希望无需任何交互即可获取性能分析信息,请查看下面的 XProf 性能分析器。
with jax.profiler.trace("/tmp/jax-trace", create_perfetto_link=True):
# Run the operations to be profiled
key = jax.random.key(0)
x = jax.random.normal(key, (5000, 5000))
y = x @ x
y.block_until_ready()
此计算完成后,程序将提示您打开一个指向 ui.perfetto.dev 的链接。当您打开链接时,Perfetto UI 将加载跟踪文件并打开可视化工具。
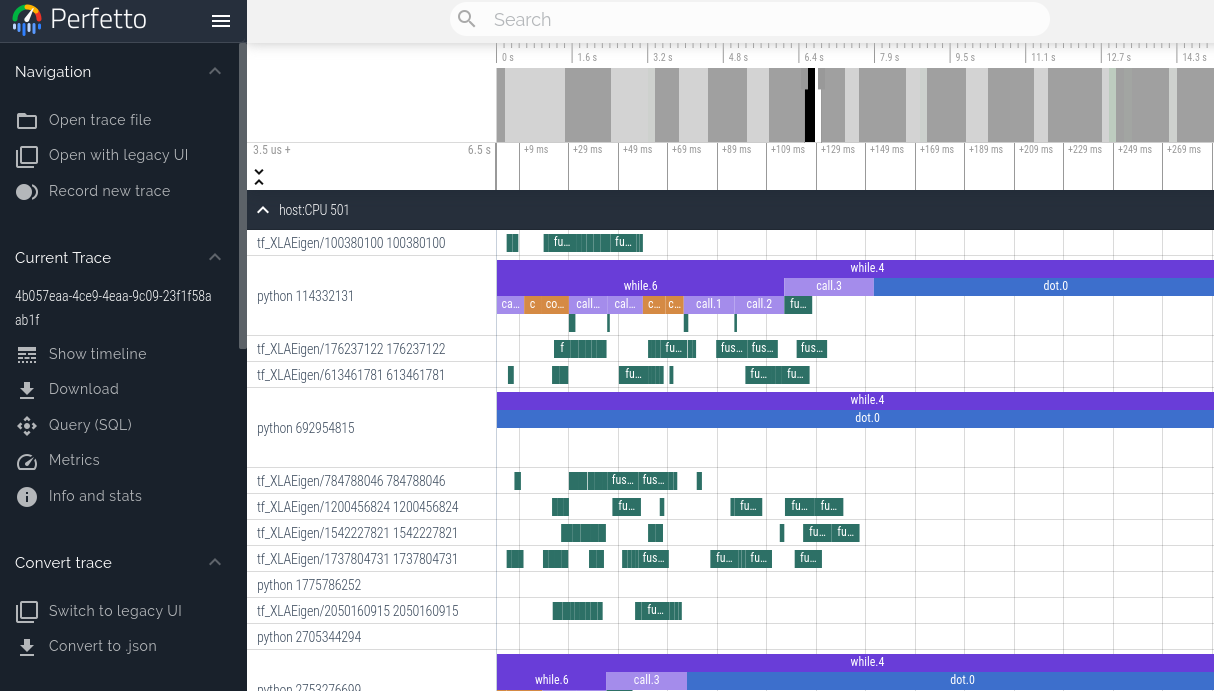
加载链接后,程序执行将继续。该链接在打开一次后即失效,但它将重定向到一个新的有效 URL。然后,您可以单击 Perfetto UI 中的“共享”按钮,为跟踪创建永久链接,以便与他人共享。
远程性能分析#
在对远程运行的代码(例如在托管虚拟机上)进行性能分析时,您需要为端口 9001 建立 SSH 隧道,以便链接正常工作。您可以使用此命令来完成
$ ssh -L 9001:127.0.0.1:9001 <user>@<host>
或者如果您正在使用 Google Cloud
$ gcloud compute ssh <machine-name> -- -L 9001:127.0.0.1:9001
手动捕获#
您可以通过调用 jax.profiler.start_server(<port>) 在感兴趣的脚本中启动性能分析服务器,而不是通过 jax.profiler.trace 以编程方式捕获跟踪。如果您只需要在脚本的某个部分激活性能分析服务器,可以通过调用 jax.profiler.stop_server() 将其关闭。
一旦脚本运行并且性能分析服务器已启动,我们可以通过运行以下命令手动捕获和跟踪
$ python -m jax.collect_profile <port> <duration_in_ms>
默认情况下,生成的跟踪信息会转储到临时目录中,但可以通过传入 --log_dir=<directory of choice> 来覆盖。此外,默认情况下,程序将提示您打开一个指向 ui.perfetto.dev 的链接。当您打开链接时,Perfetto UI 将加载跟踪文件并打开可视化工具。此功能可以通过在命令中传入 --no_perfetto_link 来禁用。或者,您也可以将 Tensorboard 指向 log_dir 来分析跟踪(请参阅下面的“XProf (Tensorboard 性能分析)”部分)。
XProf (TensorBoard 性能分析)#
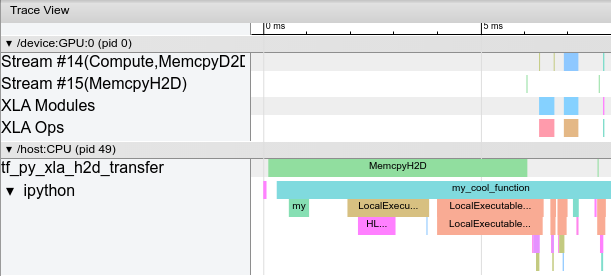
XProf 可用于对 JAX 程序进行性能分析。XProf 是获取和可视化程序性能跟踪和配置(包括 GPU 和 TPU 上的活动)的绝佳方式。最终结果如下所示
安装#
XProf 可作为 TensorBoard 的插件以及独立运行的程序使用。
pip install xprof
如果您安装了 TensorBoard,则 xprof pip 包也将安装 TensorBoard Profiler 插件。请注意仅安装一个版本的 TensorFlow 或 TensorBoard,否则您可能会遇到下面描述的“重复插件”错误。有关安装 TensorBoard 的更多信息,请参阅https://tensorflowcn.cn/guide/profiler。
使用 TensorBoard 夜间版本进行性能分析需要夜间版 XProf。
pip install tb-nightly xprof-nightly
程序化捕获#
您可以通过 jax.profiler.start_trace() 和 jax.profiler.stop_trace() 方法来检测您的代码以捕获性能分析器跟踪。调用 start_trace() 时指定要写入跟踪文件的目录。这应该与用于启动 XProf 的 --logdir 目录相同。然后,您可以使用 XProf 查看跟踪。
例如,进行性能分析器跟踪
import jax
jax.profiler.start_trace("/tmp/profile-data")
# Run the operations to be profiled
key = jax.random.key(0)
x = jax.random.normal(key, (5000, 5000))
y = x @ x
y.block_until_ready()
jax.profiler.stop_trace()
请注意 block_until_ready() 调用。我们使用它来确保设备上的执行被跟踪捕获。有关为什么这是必要的详细信息,请参阅异步调度。
您还可以使用 jax.profiler.trace() 上下文管理器作为 start_trace 和 stop_trace 的替代方案
import jax
with jax.profiler.trace("/tmp/profile-data"):
key = jax.random.key(0)
x = jax.random.normal(key, (5000, 5000))
y = x @ x
y.block_until_ready()
查看跟踪#
捕获跟踪后,您可以使用 XProf UI 查看它。
您可以通过将独立 XProf 命令指向您的日志目录来直接启动性能分析器 UI
$ xprof --port 8791 /tmp/profile-data
Attempting to start XProf server:
Log Directory: /tmp/profile-data
Port: 8791
XProf at https://:8791/ (Press CTRL+C to quit)
在浏览器中导航到提供的 URL(例如,https://:8791/)以查看配置文件。
可用的跟踪显示在左侧的“运行”下拉菜单中。选择您感兴趣的运行,然后从“工具”下拉菜单中选择 trace_viewer。您现在应该会看到执行的时间线。您可以使用 WASD 键导航跟踪,并单击或拖动以选择事件以获取更多详细信息。有关使用跟踪查看器的更多详细信息,请参阅这些 TensorFlow 文档。
通过 XProf 手动捕获#
以下是从正在运行的程序中捕获手动触发的 N 秒跟踪的说明。
启动 XProf 服务器
xprof --logdir /tmp/profile-data/
您应该能够在 https://:8791/ 加载 XProf。您可以使用
--port标志指定不同的端口。如果在远程服务器上运行 JAX,请参阅下面的在远程机器上进行性能分析。在您希望进行性能分析的 Python 程序或进程中,在开头附近添加以下内容
import jax.profiler jax.profiler.start_server(9999)
这会启动 XProf 连接的性能分析服务器。在进入下一步之前,性能分析服务器必须正在运行。使用完服务器后,您可以调用
jax.profiler.stop_server()将其关闭。如果您想对长时间运行的程序片段(例如长时间的训练循环)进行性能分析,可以将其放在程序的开头,并像往常一样启动程序。如果您想对短程序(例如微基准测试)进行性能分析,一个选项是在 IPython shell 中启动性能分析服务器,并在下一步启动捕获后使用
%run运行短程序。另一个选项是在程序开头启动性能分析服务器,并使用time.sleep()给您足够的时间来启动捕获。打开 https://:8791/,然后单击左上角的“CAPTURE PROFILE”按钮。输入“localhost:9999”作为性能分析服务 URL(这是您在上一步中启动的性能分析服务器的地址)。输入您希望进行性能分析的毫秒数,然后单击“CAPTURE”。
如果您希望进行性能分析的代码尚未运行(例如,如果您在 Python shell 中启动了性能分析服务器),请在捕获运行时运行它。
捕获完成后,XProf 应该会自动刷新。(并非所有的 XProf 性能分析功能都与 JAX 连接,因此最初可能看起来没有捕获到任何内容。)在左侧“工具”下,选择
trace_viewer。
您现在应该会看到执行的时间线。您可以使用 WASD 键导航跟踪,并单击或拖动以选择事件以在底部查看更多详细信息。有关使用跟踪查看器的更多详细信息,请参阅这些 XProf 文档。
您还可以使用以下工具
XProf 和 Tensorboard#
XProf 是为 Tensorboard 中的性能分析和跟踪捕获功能提供支持的底层工具。只要安装了 xprof,Tensorboard 中就会出现一个“Profile”选项卡。只要它指向相同的日志目录,使用它与独立启动 XProf 是相同的。这包括配置文件捕获、分析和查看功能。XProf 取代了以前推荐的 tensorboard_plugin_profile 功能。
$ tensorboard --logdir=/tmp/profile-data
[...]
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.19.0 at https://:6006/ (Press CTRL+C to quit)
添加自定义跟踪事件#
默认情况下,跟踪查看器中的事件主要是低级内部 JAX 函数。您可以通过在代码中使用 jax.profiler.TraceAnnotation 和 jax.profiler.annotate_function() 添加自己的事件和函数。
配置性能分析器选项#
start_trace 方法接受一个可选的 profiler_options 参数,该参数允许对性能分析器的行为进行精细控制。此参数应为 jax.profiler.ProfileOptions 的实例。
例如,禁用所有 Python 和主机跟踪
import jax
options = jax.profiler.ProfileOptions()
options.python_tracer_level = 0
options.host_tracer_level = 0
jax.profiler.start_trace("/tmp/profile-data", profiler_options=options)
# Run the operations to be profiled
key = jax.random.key(0)
x = jax.random.normal(key, (5000, 5000))
y = x @ x
y.block_until_ready()
jax.profiler.stop_trace()
通用选项#
host_tracer_level:设置主机端活动的跟踪级别。支持的值
0:完全禁用主机(CPU)跟踪。1:仅启用用户检测的 TraceMe 事件的跟踪(这是默认值)。2:包括级别 1 跟踪以及高级程序执行详细信息,例如昂贵的 XLA 操作。3:包括级别 2 跟踪以及更详细的低级程序执行详细信息,例如廉价的 XLA 操作。python_tracer_level:控制是否启用 Python 跟踪。支持的值
0:禁用 Python 函数调用跟踪。1:启用 Python 跟踪(这是默认值)。
高级配置选项#
tpu_trace_mode:指定 TPU 跟踪模式。支持的值
TRACE_ONLY_HOST:表示仅跟踪主机端 (CPU) 活动,不收集设备 (TPU/GPU) 跟踪。TRACE_ONLY_XLA:表示仅跟踪设备上的 XLA 级别操作。TRACE_COMPUTE:这会跟踪设备上的计算操作。TRACE_COMPUTE_AND_SYNC:这会跟踪设备上的计算操作和同步事件。如果未提供“tpu_trace_mode”,则 trace_mode 默认为 TRACE_ONLY_XLA。
tpu_num_sparse_cores_to_trace:指定在 TPU 上跟踪的稀疏核心数量。tpu_num_sparse_core_tiles_to_trace:指定在 TPU 上每个稀疏核心内跟踪的瓦片数量。tpu_num_chips_to_profile_per_task:指定每个任务要分析的 TPU 芯片数量。
例如
options = ProfileOptions()
options.advanced_configuration = {"tpu_trace_mode" : "TRACE_ONLY_HOST", "tpu_num_sparse_cores_to_trace" : 2}
如果发现任何无法识别的键或选项值,则返回 InvalidArgumentError。
故障排除#
GPU 性能分析#
在 GPU 上运行的程序应在跟踪查看器顶部附近生成 GPU 流的跟踪。如果您只看到主机跟踪,请检查您的程序日志和/或输出中是否存在以下错误消息。
如果您收到类似以下的错误:Could not load dynamic library 'libcupti.so.10.1'
完整错误
W external/org_tensorflow/tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcupti.so.10.1'; dlerror: libcupti.so.10.1: cannot open shared object file: No such file or directory
2020-06-12 13:19:59.822799: E external/org_tensorflow/tensorflow/core/profiler/internal/gpu/cupti_tracer.cc:1422] function cupti_interface_->Subscribe( &subscriber_, (CUpti_CallbackFunc)ApiCallback, this)failed with error CUPTI could not be loaded or symbol could not be found.
将 libcupti.so 的路径添加到环境变量 LD_LIBRARY_PATH。(尝试使用 locate libcupti.so 查找路径。)例如
export LD_LIBRARY_PATH=/usr/local/cuda-10.1/extras/CUPTI/lib64/:$LD_LIBRARY_PATH
如果您在执行此操作后仍然收到 Could not load dynamic library 消息,请检查 GPU 跟踪是否仍然显示在跟踪查看器中。此消息有时即使一切正常也会出现,因为它会在多个位置查找 libcupti 库。
如果您收到类似以下的错误:failed with error CUPTI_ERROR_INSUFFICIENT_PRIVILEGES
完整错误
E external/org_tensorflow/tensorflow/core/profiler/internal/gpu/cupti_tracer.cc:1445] function cupti_interface_->EnableCallback( 0 , subscriber_, CUPTI_CB_DOMAIN_DRIVER_API, cbid)failed with error CUPTI_ERROR_INSUFFICIENT_PRIVILEGES
2020-06-12 14:31:54.097791: E external/org_tensorflow/tensorflow/core/profiler/internal/gpu/cupti_tracer.cc:1487] function cupti_interface_->ActivityDisable(activity)failed with error CUPTI_ERROR_NOT_INITIALIZED
运行以下命令(请注意,这需要重启)
echo 'options nvidia "NVreg_RestrictProfilingToAdminUsers=0"' | sudo tee -a /etc/modprobe.d/nvidia-kernel-common.conf
sudo update-initramfs -u
sudo reboot now
有关此错误的更多信息,请参阅NVIDIA 的此错误文档。
在远程机器上进行性能分析#
如果您要进行性能分析的 JAX 程序在远程机器上运行,一个选项是在远程机器上运行上述所有指令(特别是,在远程机器上启动 TensorBoard 服务器),然后使用 SSH 本地端口转发从您的本地机器访问 TensorBoard Web UI。使用以下 SSH 命令将默认的 TensorBoard 端口 6006 从本地转发到远程机器
ssh -L 6006:localhost:6006 <remote server address>
或者如果您正在使用 Google Cloud
$ gcloud compute ssh <machine-name> -- -L 6006:localhost:6006
多个 TensorBoard 安装#
如果启动 TensorBoard 失败并出现类似以下错误:ValueError: Duplicate plugins for name projector
这通常是因为安装了两个版本的 TensorBoard 和/或 TensorFlow(例如,tensorflow、tf-nightly、tensorboard 和 tb-nightly pip 包都包含 TensorBoard)。卸载单个 pip 包可能导致 tensorboard 可执行文件被删除,然后很难替换,因此可能需要卸载所有内容并重新安装单个版本
pip uninstall tensorflow tf-nightly tensorboard tb-nightly xprof xprof-nightly tensorboard-plugin-profile tbp-nightly
pip install tensorboard xprof
Nsight#
NVIDIA 的 Nsight 工具可用于在 GPU 上跟踪和分析 JAX 代码。有关详细信息,请参阅 Nsight 文档。