shmap (shard_map) 用于简单的按设备代码#
sholto@, sharadmv@, jekbradbury@, zhangqiaorjc@, mattjj@
2023 年 1 月
这是提议 shard_map 的设计文档。您可能更想看 最新的用户文档。
动机#
JAX 支持两种多设备编程思路
编译器,请负责! 让编译器自动将大型数组函数分割到各个设备上。
让我直接写我想要的东西,拜托! 给我按设备编写代码和显式通信集合(collectives)的权利。
我们需要这两种思路的优秀 API,它们并非互斥,而是需要能够互相组合。
有了 pjit(现在已更名为 jit),我们有了 下一代 API 来支持第一种思路。但我们尚未真正改进第二种思路。 pmap 遵循第二种思路,但随着时间的推移,我们发现它存在 致命缺陷。 xmap 解决了这些缺陷,但它并没有完全提供按设备形状(per-device shapes),并且还包含许多其他重要想法。与此同时,出现了新的对按设备显式集合编程的需求,例如在 Efficiently Scaling Transformer Inference 中。
我们可以通过 shmap 来改进第二种思路。 shmap 是
一个简单的多设备并行 API,它允许我们编写按设备代码和显式集合,其中逻辑形状匹配按设备物理缓冲区形状,集合对应于跨设备通信;
一个
xmap的特化版本,功能有所缩减,并做了一些调整;XLA SPMD Partitioner 的“手动”模式的相当直接的暴露;
一个有趣的 Seussian(苏斯风格)名称,可以代表
shard_map,shpecialized_xmap,sholto_map, 或sharad_map。
对于 pjit 用户,shmap 是一个补充工具。它可以在 pjit 计算内部临时切换到“手动集合”模式,就像从编译器的自动分区中逃脱出来一样。这样,用户就能在大部分代码中获得 pjit 的便捷性和熟悉的 NumPy 编程模型,同时还能在需要的地方使用 shmap 手动优化集合通信。这是两全其美!
对于 pmap 用户,shmap 是一个严格的升级。它更具表现力、性能更高,并且与其他 JAX API 的组合性更好,同时不会增加基本批量数据并行的难度。
有关实际用法的更多信息,您可以跳转到 何时使用 shmap,何时使用 pjit?。如果您想知道为什么我们需要一个新的东西,或者 pmap 的问题是什么,请跳转到 为什么 pmap 或 xmap 不能解决这个问题?。或者继续阅读下一节,查看一些 shmap 示例和 API 规范。
那么,让我们看看 shmap 吧!#
TL;DR 示例(稍后会有更详细的解释)#
Sho shick
from functools import partial
import numpy as np
import jax
import jax.numpy as jnp
from jax.sharding import Mesh, PartitionSpec as P
from jax.experimental.shard_map import shard_map
mesh = jax.make_mesh((4, 2), ('i', 'j'))
a = jnp.arange( 8 * 16.).reshape(8, 16)
b = jnp.arange(16 * 32.).reshape(16, 32)
@partial(shard_map, mesh=mesh, in_specs=(P('i', 'j'), P('j', None)),
out_specs=P('i', None))
def matmul_basic(a_block, b_block):
# a_block: f32[2, 8]
# b_block: f32[8, 32]
z_partialsum = jnp.dot(a_block, b_block)
z_block = jax.lax.psum(z_partialsum, 'j')
return z_block
c = matmul_basic(a, b) # c: f32[8, 32]
注意
与
pmap不同,多并行轴不需要嵌套(或axis_index_groups);与
pmap和硬编码的xmap不同,调用者不需要进行 reshape,并且逻辑形状与按设备物理形状对应,与(非硬编码的)xmap不同;与
pmap不同,可以通过使用mesh来精确控制设备放置;与
xmap不同,只有一个用于逻辑和物理的轴名称集;结果是一个
jax.Array,可以高效地传递给pjit,与pmap不同;相同的代码可以在
pjit/jit中高效运行,与pmap不同;此代码是即时执行的(eager),因此我们可以在中间使用
pdb并打印值,与xmap的当前实现不同(尽管根据设计,没有顺序调度(sequential schedule)的xmap原则上也可以即时执行)。
这里是另一个具有完全分片结果的 matmul 变体
@partial(shard_map, mesh=mesh, in_specs=(P('i', 'j'), P('j', None)),
out_specs=P('i', 'j'))
def matmul_reduce_scatter(a_block, b_block):
# c_partialsum: f32[8/X, 32]
c_partialsum = jnp.matmul(a_block, b_block)
# c_block: f32[8/X, 32/Y]
c_block = jax.lax.psum_scatter(c_partialsum, 'j', scatter_dimension=1, tiled=True)
return c_block
c = matmul_reduce_scatter(a, b)
放慢脚步,从基础开始!#
数组轴上的降秩与保持秩映射#
我们可以将 pmap(以及 vmap 和 xmap)看作是沿着一个轴对每个数组输入进行解叠(unstacking)(例如,将一个 2D 矩阵解包成其 1D 行),将函数体应用于每个片段,然后将结果堆叠(stacking)回一起,至少在不涉及集合操作时是如此。
pmap(f, in_axes=[0], out_axes=0)(xs) == jnp.stack([f(x) for x in xs])
例如,如果 xs 的形状是 f32[8,5],那么每个 x 的形状是 f32[5],如果每个 f(x) 的形状是 f32[3,7],那么最终堆叠的结果 pmap(f)(xs) 的形状是 f32[8,3,7]。也就是说,函数体 f 的每次应用接受的输入比 pmap(f) 的相应输入的轴少一个。我们可以说这些是带有输入/输出解叠/堆叠的*降秩映射*。
逻辑上应用 f 的次数由被映射的输入轴的大小决定:例如,如果我们映射一个大小为 8 的输入轴,语义上我们得到 8 次逻辑函数应用,对于 pmap 来说,这始终对应于 8 个设备在物理上进行计算。
相比之下,shmap 没有这种降秩行为。相反,我们可以将其视为沿着输入轴进行切片(或“不拼接”)成块,应用函数体,然后将结果(再次,在不涉及集合操作时)拼接回一起。
devices = np.array(jax.devices()[:4])
m = Mesh(devices, ('i',)) # mesh.shape['i'] = 4
shard_map(f, m, in_specs=P('i'), out_specs=P('i'))(y)
==
jnp.concatenate([f(y_blk) for y_blk in jnp.split(y, 4)])
回想一下,jnp.split 会将其输入切片成相同大小的块,并且保持秩不变。因此,如果在上面的示例中 y 的形状是 f32[8,5],那么每个 y_blk 的形状是 f32[2,5],如果每个 f(y_blk) 的形状是 f32[3,7],那么最终拼接的结果 shard_map(f, ...)(y) 的形状是 f32[12,7]。所以 shmap (shard_map) 映射其输入的 shard 或块。我们可以说它是一个*保持秩的映射*,通过其输入的解拼接(unconcatenating)/拼接(concatenating)。
逻辑上应用 f 的次数由 mesh 的大小决定,而不是任何输入轴的大小:例如,如果我们有一个总大小为 4 的 mesh(即跨 4 个设备),那么语义上我们得到 4 次逻辑函数应用,对应于物理上计算它们的 4 个设备。
使用 in_specs 控制每个输入如何拆分(不拼接)和分块(tiled)#
每个 in_specs 使用 PartitionSpecs 通过名称将相应输入数组的某些轴与 mesh 轴进行匹配,表示如何将该输入拆分(或不拼接)成要应用函数体的块。这种匹配决定了 shard 的大小;当输入轴与 mesh 轴匹配时,输入将沿着该逻辑轴被拆分(不拼接)成等于相应 mesh 轴大小的块数。(如果相应的 mesh 轴大小不能整除输入数组轴大小,则会报错。)如果输入的 pspec 没有提及 mesh 轴名称,则不会在该 mesh 轴上进行拆分。例如
devices = np.array(jax.devices())
m = Mesh(devices.reshape(4, 2), ('i', 'j'))
@partial(shard_map, mesh=m, in_specs=P('i', None), out_specs=P('i', 'j'))
def f1(x_block):
print(x_block.shape)
return x_block
x1 = np.arange(12 * 12).reshape(12, 12)
y = f1(x1) # prints (3,12)
在这里,因为输入 pspec 没有提及 mesh 轴名称 'j',所以没有输入数组轴在该 mesh 轴上被拆分;同样,因为输入数组的第二轴没有与任何 mesh 轴匹配(因此也没有被拆分),函数 f1 的应用沿该轴获得了输入的完整视图。
当 mesh 轴未在输入 pspec 中提及时,我们可以总是重写成一个效率较低的程序,其中所有 mesh 轴都被提及,但调用者执行一个 jnp.tile,例如
@partial(shard_map, mesh=m, in_specs=P('i', 'j'), out_specs=P('i', 'j'))
def f2(x_block):
print(x_block.shape)
return x_block
x = np.arange(12 * 12).reshape(12, 12)
x_ = jnp.tile(x, (1, mesh.axis_size['j'])) # x_ has shape (12, 24)
y = f2(x_) # prints (3,12), and f1(x) == f2(x_)
换句话说,因为每个输入 pspec 可以提及每个 mesh 轴名称零次或一次,而不是必须提及每次名称一次,所以我们可以说,除了 jnp.split 内置于其输入之外,shard_map 还具有一个 jnp.tile,至少在逻辑上是这样(尽管根据参数的物理分片布局,分块可能不需要物理执行)。分块不是唯一的;我们也可以沿着第一个轴进行分块,并使用 pspec P(('j', 'i'), None)。
输入端允许物理数据移动,因为每个设备都需要获取相应数据的副本。
使用 out_specs 控制每个输出如何通过拼接、块转置和取消分块(untiling)来组装#
与输入端类似,每个 out_specs 通过名称将相应输出数组的某些轴与 mesh 轴进行匹配,表示如何将输出块(每个块对应一次函数体应用,或等效地对应每个物理设备)重新组装成最终输出值。例如,在上面的 f1 和 f2 示例中,out_specs 表明我们应该通过沿着两个轴拼接块结果来形成最终输出,在这两种情况下都得到一个形状为 (12,24) 的数组 y。(如果函数体输出形状,即输出块形状,其秩对于相应输出 pspec 描述的拼接来说太小,则会报错。)
当 mesh 轴名称未在输出 pspec 中提及时,它表示一个*取消分块*(un-tiling):当用户编写一个未提及 mesh 轴名称的输出 pspec 时,他们承诺输出块沿该 mesh 轴是相等的,因此只使用该轴上的一个块作为输出(而不是沿着该 mesh 轴拼接所有块)。例如,使用与上面相同的 mesh:
x = jnp.array([[3.]])
z = shard_map(lambda: x, mesh=m, in_specs=(), out_specs=P('i', 'j'))()
print(z) # prints the same as jnp.tile(x, (4, 2))
z = shard_map(lambda: x, mesh=m, in_specs=(), out_specs=P('i', None))()
print(z) # prints the same as jnp.tile(x, (4, 1)), or just jnp.tile(x, (4,))
z = shard_map(lambda: x, mesh=m, in_specs=(), out_specs=P(None, None))()
print(z) # prints the same as jnp.tile(x, (1, 1)), or just x
请注意,闭包(closing over)一个数组值的函数体等同于将其作为一个参数传递,并带有相应的 P(None, None) 输入 pspec。再举一个例子,更接近于上面的其他示例:
@partial(shard_map, mesh=m, in_specs=P('i', 'j'), out_specs=P('i', None))
def f3(x_block):
return jax.lax.psum(x_block, 'j')
x = np.arange(12 * 12).reshape(12, 12)
y3 = f3(x)
print(y3.shape) # (12,6)
请注意,结果的第二个轴大小为 6,是输入第二个轴大小的一半。在这种情况下,通过在输出 pspec 中不提及 mesh 轴名称 'j' 所表达的取消分块是安全的,因为有 psum 集合操作,它确保每个输出块沿相应的 mesh 轴是相等的。这里是另外两个示例,其中我们改变了输出 pspec 中提及的 mesh 轴:
@partial(shard_map, mesh=m, in_specs=P('i', 'j'), out_specs=P(None, 'j'))
def f4(x_block):
return jax.lax.psum(x_block, 'i')
x = np.arange(12 * 12).reshape(12, 12)
y4 = f4(x)
print(y4.shape) # (3,12)
@partial(shard_map, mesh=m, in_specs=P('i', 'j'), out_specs=P(None, None))
def f5(x_block):
return jax.lax.psum(x_block, ('i', 'j'))
y5 = f5(x)
print(y5.shape) # (3,6)
在物理方面,在输出 pspec 中未提及 mesh 轴名称会在该 mesh 轴上以复制(replicated)布局组装一个 Array,其中包含输出设备缓冲区。
在运行时没有检查输出块沿要取消分块的 mesh 轴是否确实相等,或者等效地,物理缓冲区的值是否相等,因此可以将其解释为单个逻辑数组的复制布局。但是,我们可以提供一个静态检查机制,在所有可能不正确的程序上引发错误。
因为 out_specs 可以提及 mesh 轴名称零次或一次,并且可以以任何顺序提及它们,所以我们可以说,除了 jnp.concatenate 内置于其输出之外,shard_map 还在其输出中同时内置了取消分块(untile)和块转置(block transpose)。
在输出端不允许物理数据移动,无论输出 pspec 如何。相反,out_specs 仅编码如何将块输出组装成 Arrays,或者物理上如何解释设备之间的缓冲区作为单个逻辑 Array 的物理布局。
API 规范#
from jax.sharding import Mesh
Specs = PyTree[PartitionSpec]
def shard_map(f: Callable, mesh: Mesh, in_specs: Specs, out_specs: Specs
) -> Callable:
...
其中
mesh编码了按数组排列并带有相关轴名称的设备,正如它为xmap和sharding.NamedSharding所做的那样;in_specs和out_specs是PartitionSpecs,它们可以 仿射地(affinely)提及mesh中的轴名称(而不是像xmap中的独立逻辑名称),以分别表示输入和输出的切片/不拼接以及拼接(不像pmap和xmap那样进行解叠和堆叠),其中未提及的名称分别对应复制和取消分块(断言已复制,所以给我一个副本);传递给
f的参数的形状与传递给shard_map-of-f的参数的形状相同(与pmap和xmap中秩减小的不同),并且shard_map-of-f的参数的形状是通过shard_map-of-f的对应参数的形状shape和相应的PartitionSpecspec 计算得出的,大致为tuple(sz // (1 if n is None else mesh.shape[n]) for sz, n in zip(shape, spec));函数体
f可以应用使用mesh中的名称的集合操作。
shmap 默认是即时(eager)执行的,这意味着我们逐个原始图元(primitive)分派计算,以便用户可以对完全复制的值使用 Python 控制流和交互式 pdb 调试来打印任何值。要暂存(stage out)并端到端编译一个 shmap 化的函数,只需在其周围加上 jit。其结果是 shmap 没有像 xmap 和 pmap 当前那样自己的分派和编译路径;它只是 jit 路径。
当它被暂存(例如通过一个包含的 jit)时,shmap 到 StableHLO 的降低(lowering)是微不足道的:它只涉及切换到输入的“手动 SPMD 模式”,然后在输出上切换回来。(我们目前不打算支持部分手动/部分自动的模式。)
与 pmap 的效果交互是相同的。
与自动微分的交互也与 pmap 相同(而不是尝试 xmap 的新语义,后者对应于非映射的中间量,因此 grad 的 reduce_axes 以及使 psum 转置为 pbroadcast 而不是 psum)。但因此它继承了 pmap 的一个未解决问题:在某些情况下,与其将反向传播的 psum 转置为 psum,从而执行对应于前向传播 psum 的反向传播 psum,不如将反向传播的 psum 移动到反向传播的其他位置,利用线性性。许多高级 pmap 用户通过使用 custom_vjp 来实现 psum_idrev 和 id_psumrev 函数来解决这个挑战,但由于很容易意外地使它们不平衡,所以这种技术是一个“脚部枪”(foot-cannon)。我们有一些想法可以更安全地提供此功能。
何时使用 shmap,何时使用 pjit?#
一种哲学是:几乎总是用 jit==pjit 来编写程序会更简单 — 但如果程序的某一部分被编译器优化的程度不如其潜力,那就切换到 shmap!
一个实际的例子#
这是 shmap 在 transformer 层中带有 2D 权重收集模式(论文,第 3.2.3 节,第 5 页)的可能样子。
def matmul_2D_wg_manual(xnorm, q_wi, layer):
'''Calls a custom manual implementation of matmul_reducescatter'''
# [batch, maxlen, embed.X] @ [heads.YZ, embed.X, q_wi_per_head]
# -> (matmul)
# -> [batch, maxlen, heads.YZ, q_wi_per_head]{x unreduced}
# -> (reducescatter over x into X heads, B batches)
# -> [batch, maxlen, heads.YZX, q_wi_per_head]
with jax.named_scope('q_wi'):
xnorm = intermediate_dtype(xnorm)
q_wi = matmul_reducescatter(
'bte,hed->bthd',
xnorm,
params.q_wi,
scatter_dimension=(0, 2),
axis_name='i',
layer=layer)
return q_wi
import partitioning.logical_to_physical as l2phys
def pjit_transformer_layer(
hparams: HParams, layer: int, params: weights.Layer, sin: jnp.ndarray,
cos: jnp.ndarray, kv_caches: Sequence[attention.KVCache],
x: jnp.ndarray) -> Tuple[jnp.ndarray, jnp.ndarray, jnp.ndarray]:
"""Forward pass through a single layer, returning output, K, V."""
def my_layer(t, axis=0):
"""Gets the parameters corresponding to a given layer."""
return lax.dynamic_index_in_dim(t, layer, axis=axis, keepdims=False)
# 2D: [batch.Z, time, embed.XY]
x = _with_sharding_constraint(
x, ('residual_batch', 'residual_time', 'residual_embed'))
xnorm = _layernorm(x)
# 2D: [batch, time, embed.X]
xnorm = _with_sharding_constraint(
xnorm, ('post_norm_batch', 'time', 'post_norm_embed'))
# jump into manual mode where you want to optimise
if manual:
q_wi = shard_map(matmul_2D_wg_manual, mesh
in_specs=(l2phys('post_norm_batch', 'time', 'post_norm_embed'),
l2phys('layers', 'heads', 'embed', 'q_wi_per_head')),
out_specs=l2phys('post_norm_batch', 'time', 'heads', 'q_wi_per_head'))(xnorm, q_wi, layer)
else:
q_wi = jnp.einsum('bte,hed->bthd', xnorm, my_layer(params.q_wi))
# 2D: [batch, time, heads.YZX, None]
q_wi = _with_sharding_constraint(q_wi,
('post_norm_batch', 'time', 'heads', 'qkv'))
q = q_wi[:, :, :, :hparams.qkv]
q = _rope(sin, cos, q)
# unlike in https://arxiv.org/pdf/2002.05202.pdf, PaLM implements
# swiGLU with full d_ff dimension, rather than 2/3 scaled
wi0 = q_wi[:, :, :, hparams.qkv:hparams.qkv + (hparams.ff // hparams.heads)]
wi1 = q_wi[:, :, :, hparams.qkv + (hparams.ff // hparams.heads):]
kv = jnp.einsum('bte,ezd->btzd', xnorm, my_layer(params.kv))
k = kv[:, :, 0, :hparams.qkv]
v = kv[:, :, 0, hparams.qkv:]
k = _rope(sin, cos, k)
y_att = jnp.bfloat16(attention.attend(q, k, v, kv_caches, layer))
y_mlp = special2.swish2(wi0) * wi1
# 2D: [batch, time, heads.YZX, None]
y_mlp = _with_sharding_constraint(y_mlp,
('post_norm_batch', 'time', 'heads', None))
y_fused = jnp.concatenate([y_att, y_mlp], axis=-1)
# do the second half of the mlp and the self-attn projection in parallel
y_out = jnp.einsum('bthd,hde->bte', y_fused, my_layer(params.o_wo))
# 2D: [batch.Z, time, embed.XY]
y_out = _with_sharding_constraint(
y_out, ('residual_batch', 'residual_time', 'residual_embed'))
z = y_out + x
z = _with_sharding_constraint(
z, ('residual_batch', 'residual_time', 'residual_embed'))
return z, k, v
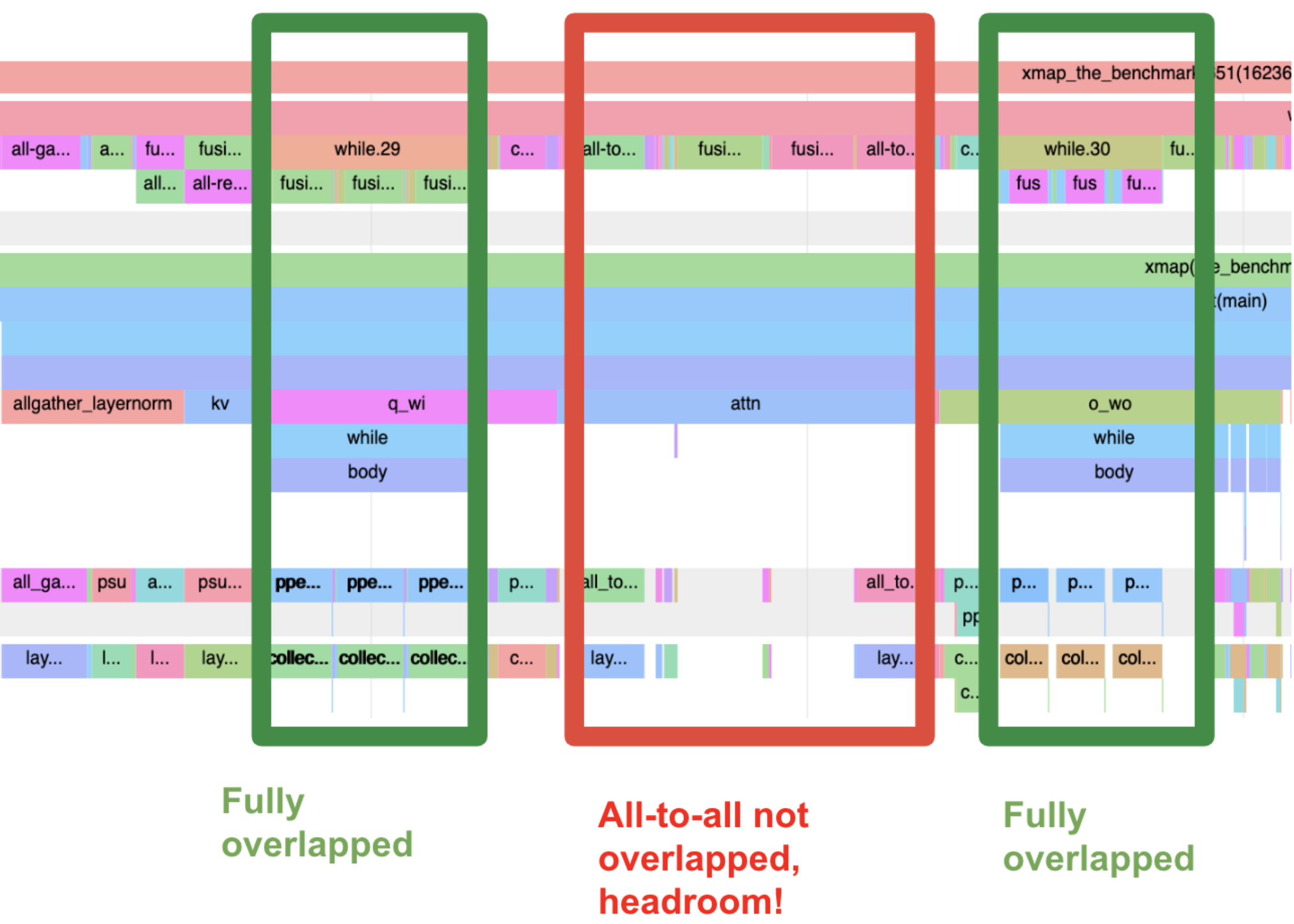
在下面的性能分析(profile)中,第一个和第二个 matmul 都被替换为手动降低(manually lowered)的版本,其中计算(fusions)与通信(ppermute)完全重叠!一个有趣的提示,表明我们正在使用一种优化延迟的变体,那就是 ppmerute 像素是抖动的 — 因为有两个重叠的 ppermute 同时使用了相反的 ICI 轴!
All-to-all 操作更难重叠,所以留在了现场。
为什么 pmap 或 xmap 不能解决这个问题?#
pmap 是我们的第一个多设备并行 API。它遵循按设备代码和显式集合的思路。但它存在重大缺陷,使其不适合当今的程序。
映射多个轴需要嵌套的
pmap。 嵌套的pmap不仅编写起来很麻烦,而且还难以控制(甚至预测)数据和计算的设备放置,并且难以保持数据分片(参见接下来的两点)。当今的程序需要多轴并行。无法控制设备放置。 尤其是在多轴并行的情况下,程序员需要控制这些轴如何与硬件资源及其通信拓扑对齐。但是(嵌套的)
pmap无法控制映射程序实例在硬件上的放置;只有一个自动的设备顺序,用户无法控制。(Gopher 使用axis_index_groups和单个非嵌套pmap基本上是一种 hack,通过将多个并行轴展平为单个轴来绕过这个问题。)与
jit/pjit的组合性。jit套pmap是一个性能陷阱(performance footgun),嵌套pmap也是如此,例如scan套pmap也是如此,因为当从内部pmap返回时,分片(sharding)不会被保留。为了保留分片,我们需要对 jaxprs 进行模式匹配,以确保我们正在处理完全嵌套的 pmap,或者一个 pmap 刚好在jit内部。此外,pjit在这方面无济于事,因为pmap针对 XLA replicas,而pjit针对 XLA SPMD Partitioner,组合两者很困难。jax.Array兼容性(以及因此的pjit兼容性)。 由于pmap输出的分片无法表示为Shardings/OpShardings,这是因为pmap的堆叠(stacking)而非拼接(concatenative)语义,pmap计算的输出无法在不经过主机(host)的情况下(或不分派一个重塑计算)传递给pjit计算。多控制器语义(以及因此的
pjit兼容性)。 多控制器pmap会拼接跨控制器的值,这工作得很好,但与单控制器pmap的堆叠语义不同。更实际地说,它排除了使用非完全可寻址(non-fully-addressable)的jax.Array输入和输出,就像我们与多控制器pjit一样。即时模式(Eager mode)。 我们没有使
pmap优先采用即时模式,尽管我们最终(在 4 年多之后!)添加了使用disable_jit()的即时操作,但pmap有jit融合到其中的事实意味着它有自己的编译和分派路径(实际上是两个分派路径:在 Python 中用于处理Tracers,在 C++ 中用于原始Array输入的性能!),这是一个沉重的实现负担。调用者需要 Reshape。 使用 8 个设备的
pmap的典型用例可能看起来是:从一个大小为 128 的批次轴开始,将其重塑为具有大小(8, 16)的两个轴,然后pmap映射第一个轴。这些重塑操作很麻烦,而且编译器经常将它们解释为复制而不是视图(view),从而增加了内存和时间使用。
当只进行批量数据并行时,这些缺陷并不算太糟糕。但当涉及更多并行性时,pmap 就无法胜任了!
xmap 作为 pmap 的下一代演进铺平了道路,并(几乎)解决了所有这些问题。shmap 沿着 xmap 的足迹前进,并以基本相同的方式解决这些问题;事实上,shmap 就像 xmap 的一个特化子集(有些人称之为“硬 xmap”子集),并做了一些调整。
对于初始原型,我们选择将 shmap 实现为一个独立于 xmap 的原始图元,因为限制它支持的功能集可以更容易地专注于核心功能。例如,shmap 不允许非映射的中间量,这使得不必担心命名轴和自动微分之间的交互更容易。此外,不必考虑所有功能对之间的交互,使得添加超出 xmap 当前实现的功能(如对即时模式的支持)更容易。
在降低代码方面,shmap 和 xmap 共享了大部分代码。我们可以在未来考虑合并两者,甚至只关注 shmap,具体取决于使用情况的演变。