JAX 类型提升语义设计#
![]()

Jake VanderPlas,2021 年 12 月
任何数值计算库在设计时面临的挑战之一是选择如何处理不同类型值之间的运算。本文档概述了 JAX 所用提升语义背后的思考过程,摘要参见 JAX 类型提升语义。
JAX 类型提升的目标#
JAX 的数值计算 API 以 NumPy 为模型,并包含一些增强功能,例如能够针对 GPU 和 TPU 等加速器进行计算。这使得采用 NumPy 的类型提升系统对 JAX 用户不利:NumPy 的类型提升规则严重偏向 64 位输出,这对于在加速器上进行计算是有问题的。GPU 和 TPU 等设备在使用 64 位浮点类型时通常会付出显著的性能代价,在某些情况下根本不支持原生 64 位浮点类型。
在 32 位整数和浮点数之间的二元运算中,可以看到这种有问题的类型提升语义的一个简单示例。
import numpy as np
np.dtype(np.int32(1) + np.float32(1))
dtype('float64')
NumPy 倾向于产生 64 位值的 长期存在的问题,这在使用 NumPy API 进行加速器计算时会遇到,目前还没有很好的解决方案。因此,JAX 试图在考虑加速器的情况下重新思考 NumPy 风格的类型提升。
退一步看:表和格#
在深入细节之前,让我们花点时间退一步,思考如何处理类型提升问题。考虑 Python 内置数值类型之间的算术运算,即 int、float 和 complex 类型。通过几行代码,我们可以生成 Python 在这些类型的值相加时使用的类型提升表。
import pandas as pd
types = [int, float, complex]
name = lambda t: t.__name__
pd.DataFrame([[name(type(t1(1) + t2(1))) for t1 in types] for t2 in types],
index=[name(t) for t in types], columns=[name(t) for t in types])
| int | float | 复数 | |
|---|---|---|---|
| int | int | float | 复数 |
| float | float | float | 复数 |
| 复数 | 复数 | 复数 | 复数 |
此表列出了 Python 的数值类型提升行为,但事实证明,还有一个更紧凑的补充表示:格 表示法,其中任意两个节点之间的上确界是它们提升到的类型。Python 提升表的格表示法要简单得多。
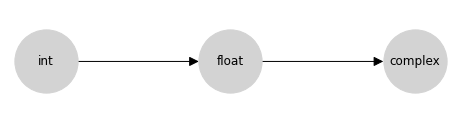
这个格是上面提升表中信息的紧凑编码。您可以通过跟踪图表到两个节点的第一个公共子节点(包括节点本身)来找到两个输入的类型提升结果;在数学上,这个公共子节点称为格上的上确界、最小上界或连接;在这里,我们将此操作称为连接。
概念上,箭头表示允许隐式类型提升从源到目标:例如,允许从整数到浮点数的隐式提升,但不允许从浮点数到整数的隐式提升。
请记住,通常情况下,并非每个有向无环图 (DAG) 都满足格的属性。格要求每对节点都存在唯一的最小上界;因此,例如,以下两个 DAG 不是格。

左边的 DAG 不是格,因为节点 B 和 C 没有上界;右边的 DAG 在两个方面都失败了:首先,节点 C 和 D 没有上界,并且对于节点 A 和 B,最小上界无法唯一确定:C 和 D 都是候选者,但它们不可排序。
类型提升格的属性#
用格来指定类型提升可以确保一些有用的属性。将格上的连接表示为 \(\vee\) 运算符,我们有:
存在性:格根据定义要求,每对元素都存在唯一的格连接:\(\forall (a, b): \exists !(a \vee b)\)
交换性:格连接是可交换的:\(\forall (a, b): a\vee b = b \vee a\)。
结合性:格连接是可结合的:\(\forall (a, b, c): a \vee (b \vee c) = (a \vee b) \vee c\)。
另一方面,这些属性暗示了它们可以表示的类型提升系统的限制;特别是,并非所有类型提升表都可以用格表示。一个现成的例子是 NumPy 的完整类型提升表;这可以通过反例快速证明:以下是 NumPy 中提升行为非结合性的三个标量类型。
import numpy as np
a, b, c = np.int8(1), np.uint8(1), np.float16(1)
print(np.dtype((a + b) + c))
print(np.dtype(a + (b + c)))
float32
float16
这样的结果可能会让用户感到惊讶:我们通常期望数学表达式映射到数学概念,因此,例如,a + b + c 应该等同于 c + b + a;x * (y + z) 应该等同于 x * y + x * z。如果类型提升是非结合的或非交换的,这些属性就不再适用。
此外,与基于表的系统相比,基于格的类型提升系统更容易概念化和理解。例如,JAX 识别 18 种不同的类型:一个由 18 个节点组成的提升格,以及它们之间稀疏且有充分理由的连接,比一个包含 324 个条目的表更容易让人记住。
因此,我们选择为 JAX 使用基于格的类型提升系统。
类别内的类型提升#
数值计算库通常提供的不只是 int、float 和 complex;在每个类别中,都有各种可能的精度,用数字表示中使用的位数表示。这里我们将考虑的类别是:
无符号整数,包括
uint8、uint16、uint32和uint64(我们将简称为u8、u16、u32、u64)。有符号整数,包括
int8、int16、int32和int64(我们将简称为i8、i16、i32、i64)。浮点数,包括
float16、float32和float64(我们将简称为f16、f32、f64)。复数浮点数,包括
complex64和complex128(我们将简称为c64、c128)。
NumPy 的类型提升语义在这些四个类别内部相对简单:有序的类型层次结构直接转化为四个独立的格,代表类别内的类型提升规则。
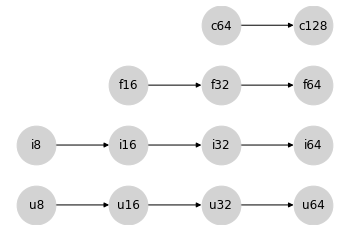
在 JAX 试图避免的提升到 64 位值的行为方面,这些同类提升语义在每个类型类别内部都没有问题:产生 64 位输出的唯一方法是输入为 64 位。
引入 Python 标量#
现在让我们考虑 Python 标量在其中的位置。
在 NumPy 中,提升行为因输入是数组还是标量而异。例如,当对两个标量进行运算时,会应用正常的提升规则。
x = np.int8(0) # int8 scalar
y = 1 # Python int = int64 scalar
(x + y).dtype
dtype('int64')
在这里,Python 值 1 被视为 int64,并且直接的类别内规则导致 int64 结果。
然而,在 Python 标量和 NumPy 数组之间的运算中,标量会服从数组的数据类型。例如:
x = np.zeros(1, dtype='int8') # int8 array
y = 1 # Python int = int64 scalar
(x + y).dtype
dtype('int8')
这里 int64 标量的位宽被忽略,服从数组的位宽。
这里还有另一个细节:当 NumPy 类型提升涉及标量时,输出数据类型取决于值:如果 Python 标量对于给定的数据类型来说太大,它将被提升到兼容的类型。
x = np.zeros(1, dtype='int8') # int8 array
y = 1000 # int64 scalar
(x + y).dtype
dtype('int16')
出于 JAX 的目的,值依赖的提升是不可行的,这是由于 JIT 编译和其他转换的性质,它们基于数据的抽象表示进行操作,而不考虑其值。
忽略值依赖效应,NumPy 类型提升的有符号整数分支可以用以下格表示,其中我们将使用 * 标记标量数据类型。
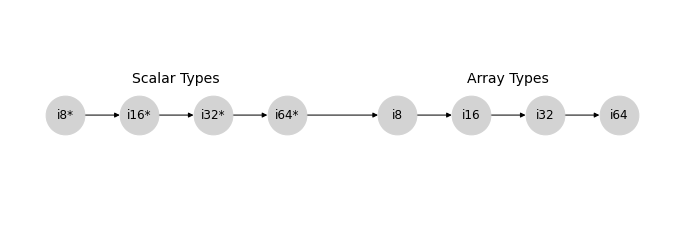
类似的模式在 uint、float 和 complex 格中也存在。
为简化起见,我们将每个标量类型类别折叠为一个节点,分别用 u*、i*、f* 和 c* 表示。我们的类别内格集现在可以这样表示:
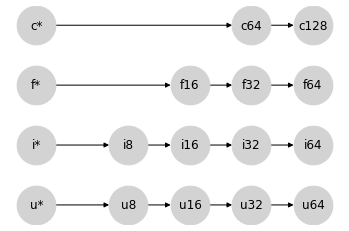
从某些方面来看,将标量放在左边是一个奇怪的选择:标量类型可能包含任何位宽的值,但当与给定类型的数组交互时,提升结果会服从数组类型。这样做的好处是,当你对数组 x 执行 x + 2 这样的操作时,x 的类型将传递给结果,无论其位宽如何。
for dtype in [np.int8, np.int16, np.int32, np.int64]:
x = np.arange(10, dtype=dtype)
assert (x + 2).dtype == dtype
这种行为为我们的 * 符号表示标量值提供了依据:* 让人联想到可以取任何所需值的通配符。
这些语义的好处是,你可以方便地用简洁的 Python 代码表达一系列操作,而无需显式地将标量转换为适当的类型。想象一下,如果不是写成这样:
3 * (x + 1) ** 2
你不得不写成这样:
np.int32(3) * (x + np.int32(1)) ** np.int32(2)
虽然明确,但数值代码读写起来会很麻烦。通过上面描述的标量提升语义,给定一个 int32 类型的数组 x,第二个语句中的类型在第一个语句中是隐式的。
合并格#
回想一下,我们开始讨论时引入了表示 Python 中类型提升的格:int -> float -> complex。让我们将其重写为 i* -> f* -> c*,并且进一步允许 i* 包含 u*(毕竟 Python 中没有无符号整数标量类型)。
将所有这些组合在一起,我们得到以下部分格,它表示 Python 标量和 NumPy 数组之间的类型提升。
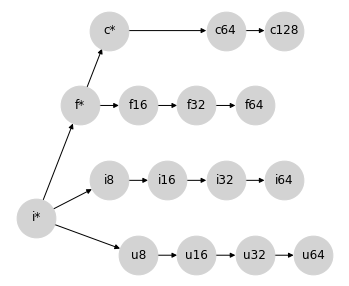
请注意,这(还)不是一个真正的格:许多节点对不存在连接。但是,我们可以将其视为一个部分格,其中某些节点对没有定义的提升行为,并且这个部分格的定义部分正确地描述了 NumPy 的数组提升行为(忽略上面提到的值依赖语义)。
这为我们提供了一个很好的框架来考虑如何填充这些未定义的提升规则,通过在图上添加连接。但是添加哪些连接呢?总的来说,我们希望任何新增的连接都满足几个属性:
提升应满足交换性和结合性:换句话说,图应保持为(部分)格。
提升不应允许完全丢弃数据组件:例如,我们不应将
complex提升到float,因为它会丢弃任何虚部。提升不应导致未处理的溢出。例如,
uint32的最大可能值是int32的两倍,因此我们不应隐式地将uint32提升到int32。尽可能,提升应避免精度损失。例如,
int64值可能具有 64 位的尾数,因此将int64提升到float64代表可能的精度损失。但是,可表示的最大float64大于可表示的最大int64,因此在这种情况下,标准 #3 仍然得到满足。尽可能,二元提升应避免产生比输入更宽的类型。这是为了确保 JAX 的隐式提升对基于加速器的工作流程友好,在这些工作流程中,用户通常希望将类型限制为 32 位(或在某些情况下 16 位)值。
格上的每个新连接都为用户带来了一定程度的便利(一组新的可以交互而无需显式转换的类型),但如果违反了上述任何标准,便利性可能会付出过高的代价。开发一个完整的提升格需要在这两者之间取得平衡。
混合提升:浮点数和复数#
让我们从可能最简单的情况开始,即浮点数和复数之间的提升。
复数由成对的浮点数组成,因此我们有它们之间自然的提升路径:将浮点数转换为复数,同时保持实部的宽度。就我们部分格的表示而言,它看起来是这样的:
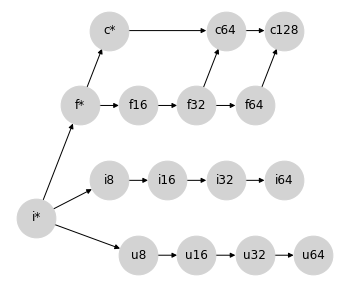
这恰好表示了 NumPy 在混合浮点/复数类型提升中使用的语义。
混合提升:有符号和无符号整数#
对于下一个案例,让我们考虑一个稍微困难一点的问题:有符号和无符号整数之间的提升。例如,在将 uint8 提升为有符号整数时,需要多少位?
乍一看,您可能会认为将 uint8 提升到 int8 是自然的;但最大的 uint8 数字在 int8 中是无法表示的。因此,将无符号整数提升到具有两倍位数的整数更有意义;这种提升行为可以通过向提升格添加以下连接来表示:
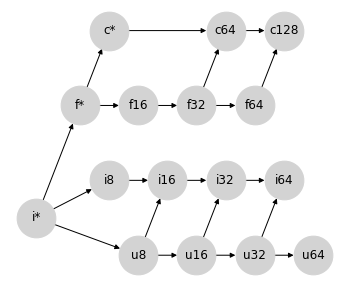
同样,这里添加的连接正是 NumPy 在混合整数提升中实现的提升语义。
如何处理 uint64?#
混合有符号/无符号整数提升的方法遗漏了一个类型:uint64。遵循上述模式,涉及 uint64 的混合整数运算的结果应该是 int128,但这并非标准的可用数据类型。
NumPy 在此处的选择是提升到 float64。
(np.uint64(1) + np.int64(1)).dtype
dtype('float64')
然而,这可能是一个令人惊讶的约定:这是整数类型提升的唯一一次不产生整数结果。目前,我们将 uint64 提升设为未定义,稍后会回来处理。
混合提升:整数和浮点数#
在将整数提升为浮点数时,我们可以从与有符号和无符号整数混合提升相同的思路开始。16 位有符号或无符号整数无法以全精度表示为 16 位浮点数,后者只有 10 位尾数。因此,将整数提升为位数为两倍的浮点数可能很有意义。
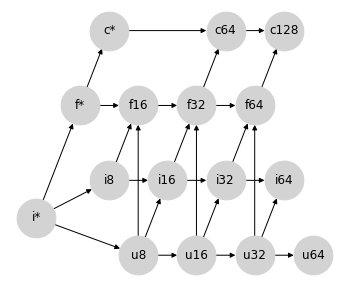
这实际上是 NumPy 类型提升所做的,但这样做会破坏图的格属性:例如,对{i8, u8} 的组合不再具有唯一的最小上界:可能性是i16 和f16,它们在图上不可排序。事实证明,这就是上面强调的 NumPy 非结合类型提升的来源。
我们能否提出一种 NumPy 提升规则的修改,使其满足格属性,同时又能为混合类型提升提供合理的结果?我们可以采取几种方法。
选项 0:将整数/浮点数混合精度设为未定义#
为了使行为完全可预测(以牺牲一些用户便利性为代价),一个可以辩护的选择是将除 Python 标量之外的任何混合整数/浮点数提升都设为未定义,停留在上一节的部分格。缺点是用户在对整数和浮点数进行运算时需要显式类型转换。
选项 1:避免所有精度损失#
如果我们的重点是无论如何都要避免精度损失,我们可以通过将无符号整数通过现有的有符号整数路径提升到浮点数来恢复格属性。
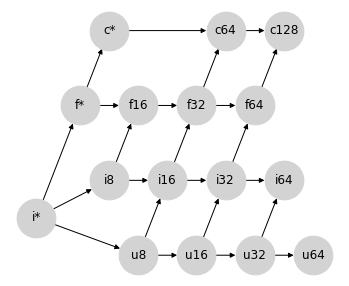
这种方法的一个缺点是它仍然将 int64 和 uint64 的提升设为未定义,因为没有标准的浮点类型具有足够的尾数位数来表示它们的完整值范围。我们可以放宽精度限制并完成格,通过从 i64->f64 和 u64->f64 绘制连接,但这些链接会违背此提升方案的初衷。
这种方法的第二个缺点是,这种格使得很难找到一个合适的位置来插入 bfloat16(见下文),同时保持格属性。
这种方法的第三个缺点,对于 JAX 的加速器后端更为重要,是一些运算的结果类型远超所需;例如,uint16 和 float16 之间的混合运算会提升到 float64,这并不理想。
选项 2:避免大多数不必要的宽度提升#
为了解决不必要的宽度提升问题,我们可以接受整数/浮点数提升中存在一些精度损失的可能性,将有符号整数提升为相同位宽的浮点数。
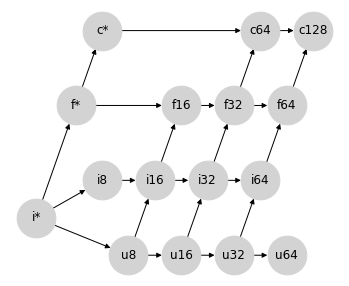
虽然这确实允许整数和浮点数之间进行会丢失精度的提升,但这些提升不会错误地表示结果的数量级:尽管浮点数的尾数不足以表示所有值,但指数足以近似它们。
这种方法还允许从 int64 到 float64 的自然提升路径,尽管 uint64 在此方案中仍然无法提升。尽管如此,与之前相比,从 u64 到 f64 的连接更容易证明是合理的。
这种提升方案仍然会导致一些不必要的宽度提升路径;例如,float32 和 uint32 之间的运算结果是 float64。此外,这种格使得很难找到一个合适的位置来插入 bfloat16(见下文),同时保持格属性。
选项 3:避免所有不必要的宽度提升#
如果我们愿意从根本上改变对整数和浮点数提升的看法,就可以避免所有不理想的 64 位提升。就像标量总是服从数组类型的位宽一样,我们可以让整数总是服从浮点类型的位宽。
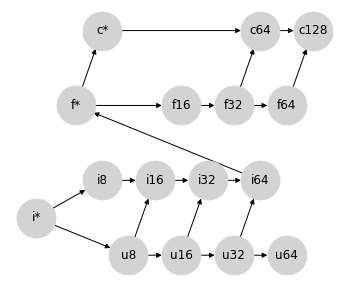
这涉及到一点技巧:之前我们使用 f* 来表示标量类型。在这个格中,f* 可能会应用于混合计算的数组输出。我们不是将 f* 看作标量,而是将其视为一种特殊的 float 值,具有不同的提升规则:在 JAX 中,我们称之为弱浮点数;见下文。
这种方法的好处是,除了无符号整数之外,它避免了所有不必要的宽度提升:你永远无法在没有 64 位输入的情况下获得 f64 输出,也无法在没有 32 位输入的情况下获得 f32 输出:这为在加速器上工作提供了便利的语义,同时避免了无意的 64 位值。
这种将浮点数类型置于首位的特性与 PyTorch 的类型提升行为相似。这个格碰巧也生成了一个非常接近 JAX 最初的临时类型提升方案的提升表,该方案不是基于格的,但具有将浮点数类型置于首位的特性。
这个格另外提供了一个自然的位置来插入 bfloat16,而无需在 bf16 和 f16 之间施加排序。
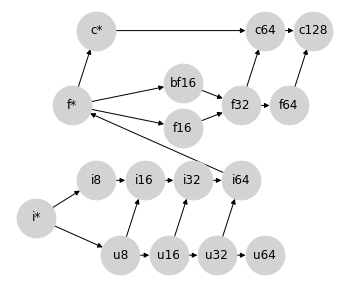
这一点很重要,因为 f16 和 bf16 是不可比较的,因为它们使用位的方式不同:bf16 以较低的精度表示较大的范围,而 f16 以较高的精度表示较小的范围。
然而,这些优势也带来了一些权衡:
混合浮点/整数提升极易导致精度损失:例如,
int64(最大值为 \(9.2 \times 10^{18}\))可以提升为float16(最大值为 \(6.5 \times 10^4\)),这意味着大多数可表示的值将变为inf。如上所述,
f*不再可以被视为“标量类型”,而是另一种float64。在 JAX 的术语中,这被称为弱类型,因为它表示为 64 位,但在与其他值的提升中,它仅弱地遵循此位宽度。
请注意,这种方法仍然没有回答 uint64 的提升问题,尽管将 u64 连接到 f* 以闭合格也许是合理的。
JAX 中的类型提升#
在设计 JAX 的类型提升语义时,我们牢记了这些想法,并严重依赖于以下几点:
我们选择将 JAX 的类型提升语义约束在满足格属性的图上:这是为了确保结合性和交换性,但也允许语义通过 DAG 紧凑地描述,而不是需要一个大表。
我们倾向于避免不必要地提升到更宽类型的语义,尤其是在浮点值方面,以便于在加速器上进行计算。
如果需要维护 (1) 和 (2),我们愿意接受混合类型提升中潜在的精度损失(但不是数量级损失)。
考虑到这一点,JAX 采用了选项 3。或者更确切地说,是选项 3 的一个轻微修改版本,它在 u64 和 f* 之间绘制连接,以创建一个真正的格。为了清晰起见,重新排列节点后,JAX 的类型提升格如下所示:
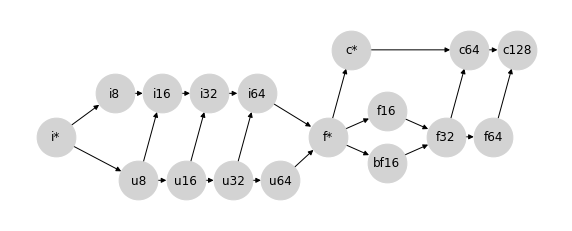
此选择产生的行为总结在 JAX 类型提升语义中。值得注意的是,除了包含较大的无符号类型(u16、u32、u64)以及关于标量/弱类型(i*、f*、c*)行为的细节之外,这种类型提升方案与 PyTorch 选择的方案非常相似。
对于感兴趣的读者,附录打印了 NumPy、Tensorflow、PyTorch 和 JAX 使用的完整提升表。
附录:类型提升表示例#
以下是一些 Python 数组计算库实现的隐式类型提升表的示例。
NumPy 类型提升#
请注意,NumPy 不包含 bfloat16 数据类型,并且下表忽略了值依赖效应。
| b | u8 | u16 | u32 | u64 | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i* | f* | c* | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| b | b | u8 | u16 | u32 | u64 | i8 | i16 | i32 | i64 | - | f16 | f32 | f64 | c64 | c128 | i64 | f64 | c128 |
| u8 | u8 | u8 | u16 | u32 | u64 | i16 | i16 | i32 | i64 | - | f16 | f32 | f64 | c64 | c128 | u8 | f64 | c128 |
| u16 | u16 | u16 | u16 | u32 | u64 | i32 | i32 | i32 | i64 | - | f32 | f32 | f64 | c64 | c128 | u16 | f64 | c128 |
| u32 | u32 | u32 | u32 | u32 | u64 | i64 | i64 | i64 | i64 | - | f64 | f64 | f64 | c128 | c128 | u32 | f64 | c128 |
| u64 | u64 | u64 | u64 | u64 | u64 | f64 | f64 | f64 | f64 | - | f64 | f64 | f64 | c128 | c128 | u64 | f64 | c128 |
| i8 | i8 | i16 | i32 | i64 | f64 | i8 | i16 | i32 | i64 | - | f16 | f32 | f64 | c64 | c128 | i8 | f64 | c128 |
| i16 | i16 | i16 | i32 | i64 | f64 | i16 | i16 | i32 | i64 | - | f32 | f32 | f64 | c64 | c128 | i16 | f64 | c128 |
| i32 | i32 | i32 | i32 | i64 | f64 | i32 | i32 | i32 | i64 | - | f64 | f64 | f64 | c128 | c128 | i32 | f64 | c128 |
| i64 | i64 | i64 | i64 | i64 | f64 | i64 | i64 | i64 | i64 | - | f64 | f64 | f64 | c128 | c128 | i64 | f64 | c128 |
| bf16 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| f16 | f16 | f16 | f32 | f64 | f64 | f16 | f32 | f64 | f64 | - | f16 | f32 | f64 | c64 | c128 | f16 | f16 | c64 |
| f32 | f32 | f32 | f32 | f64 | f64 | f32 | f32 | f64 | f64 | - | f32 | f32 | f64 | c64 | c128 | f32 | f32 | c64 |
| f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | - | f64 | f64 | f64 | c128 | c128 | f64 | f64 | c128 |
| c64 | c64 | c64 | c64 | c128 | c128 | c64 | c64 | c128 | c128 | - | c64 | c64 | c128 | c64 | c128 | c64 | c64 | c64 |
| c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | - | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 |
| i* | i64 | u8 | u16 | u32 | u64 | i8 | i16 | i32 | i64 | - | f16 | f32 | f64 | c64 | c128 | i64 | f64 | c128 |
| f* | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | - | f16 | f32 | f64 | c64 | c128 | f64 | f64 | c128 |
| c* | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | - | c64 | c64 | c128 | c64 | c128 | c128 | c128 | c128 |
Tensorflow 类型提升#
Tensorflow 避免定义隐式类型提升,除了 Python 标量在有限情况下。该表是不对称的,因为在 tf.add(x, y) 中,y 的类型必须可强制转换为 x 的类型。
| b | u8 | u16 | u32 | u64 | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i* | f* | c* | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| b | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| u8 | - | u8 | - | - | - | - | - | - | - | - | - | - | - | - | - | u8 | - | - |
| u16 | - | - | u16 | - | - | - | - | - | - | - | - | - | - | - | - | u16 | - | - |
| u32 | - | - | - | u32 | - | - | - | - | - | - | - | - | - | - | - | u32 | - | - |
| u64 | - | - | - | - | u64 | - | - | - | - | - | - | - | - | - | - | u64 | - | - |
| i8 | - | - | - | - | - | i8 | - | - | - | - | - | - | - | - | - | i8 | - | - |
| i16 | - | - | - | - | - | - | i16 | - | - | - | - | - | - | - | - | i16 | - | - |
| i32 | - | - | - | - | - | - | - | i32 | - | - | - | - | - | - | - | i32 | - | - |
| i64 | - | - | - | - | - | - | - | - | i64 | - | - | - | - | - | - | i64 | - | - |
| bf16 | - | - | - | - | - | - | - | - | - | bf16 | - | - | - | - | - | bf16 | bf16 | - |
| f16 | - | - | - | - | - | - | - | - | - | - | f16 | - | - | - | - | f16 | f16 | - |
| f32 | - | - | - | - | - | - | - | - | - | - | - | f32 | - | - | - | f32 | f32 | - |
| f64 | - | - | - | - | - | - | - | - | - | - | - | - | f64 | - | - | f64 | f64 | - |
| c64 | - | - | - | - | - | - | - | - | - | - | - | - | - | c64 | - | c64 | c64 | c64 |
| c128 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | c128 | c128 | c128 | c128 |
| i* | - | - | - | - | - | - | - | i32 | - | - | - | - | - | - | - | i32 | - | - |
| f* | - | - | - | - | - | - | - | - | - | - | - | f32 | - | - | - | f32 | f32 | - |
| c* | - | - | - | - | - | - | - | - | - | - | - | - | - | - | c128 | c128 | c128 | c128 |
PyTorch 类型提升#
请注意,torch 不包含大于 uint8 的无符号整数类型。除了这一点以及关于与标量/弱类型提升的一些细节之外,该表接近 jax.numpy 使用的表。
| b | u8 | u16 | u32 | u64 | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i* | f* | c* | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| b | b | u8 | - | - | - | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i64 | f32 | c64 |
| u8 | u8 | u8 | - | - | - | i16 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | u8 | f32 | c64 |
| u16 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| u32 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| u64 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| i8 | i8 | i16 | - | - | - | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i8 | f32 | c64 |
| i16 | i16 | i16 | - | - | - | i16 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i16 | f32 | c64 |
| i32 | i32 | i32 | - | - | - | i32 | i32 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i32 | f32 | c64 |
| i64 | i64 | i64 | - | - | - | i64 | i64 | i64 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i64 | f32 | c64 |
| bf16 | bf16 | bf16 | - | - | - | bf16 | bf16 | bf16 | bf16 | bf16 | f32 | f32 | f64 | c64 | c128 | bf16 | bf16 | c64 |
| f16 | f16 | f16 | - | - | - | f16 | f16 | f16 | f16 | f32 | f16 | f32 | f64 | c64 | c128 | f16 | f16 | c64 |
| f32 | f32 | f32 | - | - | - | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f64 | c64 | c128 | f32 | f32 | c64 |
| f64 | f64 | f64 | - | - | - | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | c128 | c128 | f64 | f64 | c128 |
| c64 | c64 | c64 | - | - | - | c64 | c64 | c64 | c64 | c64 | c64 | c64 | c128 | c64 | c128 | c64 | c64 | c64 |
| c128 | c128 | c128 | - | - | - | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 |
| i* | i64 | u8 | - | - | - | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i64 | f32 | c64 |
| f* | f32 | f32 | - | - | - | f32 | f32 | f32 | f32 | bf16 | f16 | f32 | f64 | c64 | c128 | f32 | f64 | c64 |
| c* | c64 | c64 | - | - | - | c64 | c64 | c64 | c64 | c64 | c64 | c64 | c128 | c64 | c128 | c64 | c64 | c128 |
JAX 类型提升:jax.numpy#
jax.numpy 遵循 https://jax.net.cn/en/latest/type_promotion.html 上列出的类型提升规则。这里我们使用 i*、f*、c* 来表示 Python 标量和弱类型数组。
| b | u8 | u16 | u32 | u64 | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i* | f* | c* | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| b | b | u8 | u16 | u32 | u64 | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i* | f* | c* |
| u8 | u8 | u8 | u16 | u32 | u64 | i16 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | u8 | f* | c* |
| u16 | u16 | u16 | u16 | u32 | u64 | i32 | i32 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | u16 | f* | c* |
| u32 | u32 | u32 | u32 | u32 | u64 | i64 | i64 | i64 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | u32 | f* | c* |
| u64 | u64 | u64 | u64 | u64 | u64 | f* | f* | f* | f* | bf16 | f16 | f32 | f64 | c64 | c128 | u64 | f* | c* |
| i8 | i8 | i16 | i32 | i64 | f* | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i8 | f* | c* |
| i16 | i16 | i16 | i32 | i64 | f* | i16 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i16 | f* | c* |
| i32 | i32 | i32 | i32 | i64 | f* | i32 | i32 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i32 | f* | c* |
| i64 | i64 | i64 | i64 | i64 | f* | i64 | i64 | i64 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i64 | f* | c* |
| bf16 | bf16 | bf16 | bf16 | bf16 | bf16 | bf16 | bf16 | bf16 | bf16 | bf16 | f32 | f32 | f64 | c64 | c128 | bf16 | bf16 | c64 |
| f16 | f16 | f16 | f16 | f16 | f16 | f16 | f16 | f16 | f16 | f32 | f16 | f32 | f64 | c64 | c128 | f16 | f16 | c64 |
| f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f32 | f64 | c64 | c128 | f32 | f32 | c64 |
| f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | c128 | c128 | f64 | f64 | c128 |
| c64 | c64 | c64 | c64 | c64 | c64 | c64 | c64 | c64 | c64 | c64 | c64 | c64 | c128 | c64 | c128 | c64 | c64 | c64 |
| c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 | c128 |
| i* | i* | u8 | u16 | u32 | u64 | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i* | f* | c* |
| f* | f* | f* | f* | f* | f* | f* | f* | f* | f* | bf16 | f16 | f32 | f64 | c64 | c128 | f* | f* | c* |
| c* | c* | c* | c* | c* | c* | c* | c* | c* | c* | c64 | c64 | c64 | c128 | c64 | c128 | c* | c* | c* |
JAX 类型提升:jax.lax#
jax.lax 是更底层的,不进行任何隐式提升。这里我们使用 i*、f*、c* 来表示 Python 标量和弱类型数组。
| b | u8 | u16 | u32 | u64 | i8 | i16 | i32 | i64 | bf16 | f16 | f32 | f64 | c64 | c128 | i* | f* | c* | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| b | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| u8 | - | u8 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| u16 | - | - | u16 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| u32 | - | - | - | u32 | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| u64 | - | - | - | - | u64 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| i8 | - | - | - | - | - | i8 | - | - | - | - | - | - | - | - | - | - | - | - |
| i16 | - | - | - | - | - | - | i16 | - | - | - | - | - | - | - | - | - | - | - |
| i32 | - | - | - | - | - | - | - | i32 | - | - | - | - | - | - | - | - | - | - |
| i64 | - | - | - | - | - | - | - | - | i64 | - | - | - | - | - | - | i64 | - | - |
| bf16 | - | - | - | - | - | - | - | - | - | bf16 | - | - | - | - | - | - | - | - |
| f16 | - | - | - | - | - | - | - | - | - | - | f16 | - | - | - | - | - | - | - |
| f32 | - | - | - | - | - | - | - | - | - | - | - | f32 | - | - | - | - | - | - |
| f64 | - | - | - | - | - | - | - | - | - | - | - | - | f64 | - | - | - | f64 | - |
| c64 | - | - | - | - | - | - | - | - | - | - | - | - | - | c64 | - | - | - | - |
| c128 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | c128 | - | - | c128 |
| i* | - | - | - | - | - | - | - | - | i64 | - | - | - | - | - | - | i* | - | - |
| f* | - | - | - | - | - | - | - | - | - | - | - | - | f64 | - | - | - | f* | - |
| c* | - | - | - | - | - | - | - | - | - | - | - | - | - | - | c128 | - | - | c* |