自定义导数规则#
![]()

在 JAX 中定义微分规则有两种方式:
使用
jax.custom_jvp和jax.custom_vjp为已可进行 JAX 转换的 Python 函数定义自定义微分规则;以及定义新的
core.Primitive实例及其所有转换规则,例如调用其他系统(如求解器、模拟器或通用数值计算系统)中的函数。
本笔记本关注第一种方式。要了解第二种方式,请参阅关于添加原语的笔记本。
有关 JAX 自动微分 API 的介绍,请参阅自动微分手册。本笔记本假定您对 jax.jvp 和 jax.grad 以及 JVP 和 VJP 的数学含义有所了解。
概述#
使用 jax.custom_jvp 的自定义 JVP#
import jax.numpy as jnp
from jax import custom_jvp
@custom_jvp
def f(x, y):
return jnp.sin(x) * y
@f.defjvp
def f_jvp(primals, tangents):
x, y = primals
x_dot, y_dot = tangents
primal_out = f(x, y)
tangent_out = jnp.cos(x) * x_dot * y + jnp.sin(x) * y_dot
return primal_out, tangent_out
from jax import jvp, grad
print(f(2., 3.))
y, y_dot = jvp(f, (2., 3.), (1., 0.))
print(y)
print(y_dot)
print(grad(f)(2., 3.))
2.7278922
2.7278922
-1.2484405
-1.2484405
# Equivalent alternative using the defjvps convenience wrapper
@custom_jvp
def f(x, y):
return jnp.sin(x) * y
f.defjvps(lambda x_dot, primal_out, x, y: jnp.cos(x) * x_dot * y,
lambda y_dot, primal_out, x, y: jnp.sin(x) * y_dot)
print(f(2., 3.))
y, y_dot = jvp(f, (2., 3.), (1., 0.))
print(y)
print(y_dot)
print(grad(f)(2., 3.))
2.7278922
2.7278922
-1.2484405
-1.2484405
使用 jax.custom_vjp 的自定义 VJP#
from jax import custom_vjp
@custom_vjp
def f(x, y):
return jnp.sin(x) * y
def f_fwd(x, y):
# Returns primal output and residuals to be used in backward pass by f_bwd.
return f(x, y), (jnp.cos(x), jnp.sin(x), y)
def f_bwd(res, g):
cos_x, sin_x, y = res # Gets residuals computed in f_fwd
return (cos_x * g * y, sin_x * g)
f.defvjp(f_fwd, f_bwd)
print(grad(f)(2., 3.))
-1.2484405
示例问题#
为了了解 jax.custom_jvp 和 jax.custom_vjp 旨在解决哪些问题,我们来看几个示例。下一节将更详细地介绍 jax.custom_jvp 和 jax.custom_vjp API。
数值稳定性#
jax.custom_jvp 的一个应用是提高微分的数值稳定性。
假设我们要编写一个名为 log1pexp 的函数,它计算 \(x \mapsto \log ( 1 + e^x )\)。我们可以使用 jax.numpy 来编写它。
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
log1pexp(3.)
Array(3.0485873, dtype=float32, weak_type=True)
由于它是用 jax.numpy 编写的,因此它可以进行 JAX 转换。
from jax import jit, grad, vmap
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
但是这里潜藏着一个数值稳定性问题。
print(grad(log1pexp)(100.))
nan
这看起来不对!毕竟,\(x \mapsto \log (1 + e^x)\) 的导数是 \(x \mapsto \frac{e^x}{1 + e^x}\),所以对于较大的 \(x\) 值,我们期望结果接近 1。
通过查看梯度计算的 jaxpr,我们可以更深入地了解正在发生的事情。
from jax import make_jaxpr
make_jaxpr(grad(log1pexp))(100.)
{ lambda ; a:f32[]. let
b:f32[] = exp a
c:f32[] = add 1.0:f32[] b
_:f32[] = log c
d:f32[] = div 1.0:f32[] c
e:f32[] = mul d b
in (e,) }
逐步分析 jaxpr 的求值过程,我们可以看到最后一行将涉及浮点运算会分别四舍五入到 0 和 \(\infty\) 的值的乘法,这绝不是一个好主意。也就是说,对于较大的 x,我们实际上是在计算 lambda x: (1 / (1 + jnp.exp(x))) * jnp.exp(x),这实际上会变成 0. * jnp.inf。
与其生成如此大和小的值,并寄希望于浮点数无法总是提供的抵消,我们宁愿将导数函数表达为更数值稳定的程序。特别是,我们可以编写一个程序,更精确地计算等价的数学表达式 \(1 - \frac{1}{1 + e^x}\),而不会出现抵消问题。
这个问题很有趣,因为尽管我们对 log1pexp 的定义已经可以进行 JAX 微分(并使用 jit、vmap 等进行转换),但我们不满意将标准自动微分规则应用于组成 log1pexp 的原语并组合结果。相反,我们希望指定整个函数 log1pexp 应该如何作为一个单元进行微分,从而更好地安排这些指数运算。
这是已可进行 JAX 转换的 Python 函数的自定义导数规则的一个应用:指定复合函数应如何微分,同时仍将其原始 Python 定义用于其他转换(如 jit、vmap 等)。
以下是使用 jax.custom_jvp 的解决方案。
from jax import custom_jvp
@custom_jvp
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
@log1pexp.defjvp
def log1pexp_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = log1pexp(x)
ans_dot = (1 - 1/(1 + jnp.exp(x))) * x_dot
return ans, ans_dot
print(grad(log1pexp)(100.))
1.0
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
这是一个 defjvps 便利封装器,用于表达相同的内容。
@custom_jvp
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
log1pexp.defjvps(lambda t, ans, x: (1 - 1/(1 + jnp.exp(x))) * t)
print(grad(log1pexp)(100.))
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
1.0
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
强制执行微分约定#
一个相关的应用是强制执行微分约定,可能是在边界处。
考虑函数 \(f : \mathbb{R}_+ \to \mathbb{R}_+\),其中 \(f(x) = \frac{x}{1 + \sqrt{x}}\),我们取 \(\mathbb{R}_+ = [0, \infty)\)。我们可能像这样实现 \(f\) 函数:
def f(x):
return x / (1 + jnp.sqrt(x))
作为 \(\mathbb{R}\)(整个实数线)上的数学函数,\(f\) 在零点不可微分(因为定义导数的极限从左侧不存在)。相应地,自动微分会产生一个 nan 值。
print(grad(f)(0.))
nan
但从数学上讲,如果我们将 \(f\) 视为 \(\mathbb{R}_+\) 上的函数,那么它在 0 点是可微分的 [Rudin 的《数学分析原理》定义 5.1,或 Tao 的《分析I》第三版定义 10.1.1 和示例 10.1.6]。或者,我们可能会约定,希望考虑从右侧的定向导数。因此,Python 函数 grad(f) 在 0.0 处返回一个合理的值,即 1.0。默认情况下,JAX 的微分机制假定所有函数都在 \(\mathbb{R}\) 上定义,因此此处不会产生 1.0。
我们可以使用自定义 JVP 规则!特别是,我们可以在 \(\mathbb{R}_+\) 上根据导数函数 \(x \mapsto \frac{\sqrt{x} + 2}{2(\sqrt{x} + 1)^2}\) 来定义 JVP 规则,
@custom_jvp
def f(x):
return x / (1 + jnp.sqrt(x))
@f.defjvp
def f_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = f(x)
ans_dot = ((jnp.sqrt(x) + 2) / (2 * (jnp.sqrt(x) + 1)**2)) * x_dot
return ans, ans_dot
print(grad(f)(0.))
1.0
这是便利封装器版本。
@custom_jvp
def f(x):
return x / (1 + jnp.sqrt(x))
f.defjvps(lambda t, ans, x: ((jnp.sqrt(x) + 2) / (2 * (jnp.sqrt(x) + 1)**2)) * t)
print(grad(f)(0.))
1.0
梯度裁剪#
虽然在某些情况下我们希望表达数学微分计算,但在其他情况下,我们甚至可能希望脱离数学来调整自动微分执行的计算。一个典型的例子是反向模式梯度裁剪。
对于梯度裁剪,我们可以使用 jnp.clip 以及 jax.custom_vjp 的仅反向模式规则。
from functools import partial
from jax import custom_vjp
@custom_vjp
def clip_gradient(lo, hi, x):
return x # identity function
def clip_gradient_fwd(lo, hi, x):
return x, (lo, hi) # save bounds as residuals
def clip_gradient_bwd(res, g):
lo, hi = res
return (None, None, jnp.clip(g, lo, hi)) # use None to indicate zero cotangents for lo and hi
clip_gradient.defvjp(clip_gradient_fwd, clip_gradient_bwd)
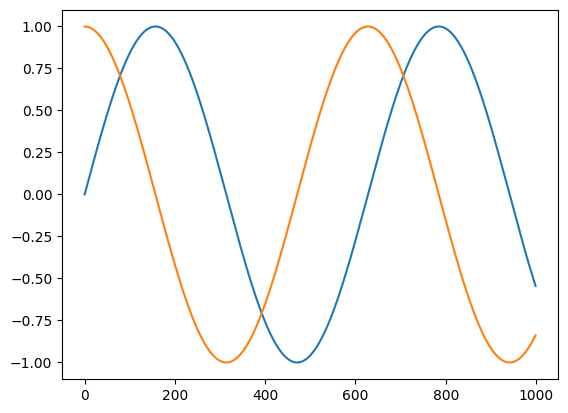
import matplotlib.pyplot as plt
from jax import vmap
t = jnp.linspace(0, 10, 1000)
plt.plot(jnp.sin(t))
plt.plot(vmap(grad(jnp.sin))(t))
[<matplotlib.lines.Line2D at 0x78d1e10ff860>]
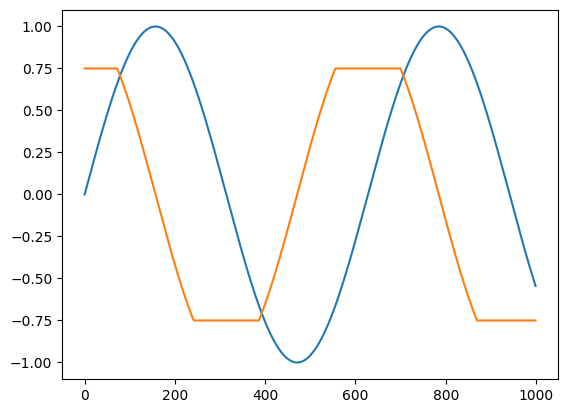
def clip_sin(x):
x = clip_gradient(-0.75, 0.75, x)
return jnp.sin(x)
plt.plot(clip_sin(t))
plt.plot(vmap(grad(clip_sin))(t))
[<matplotlib.lines.Line2D at 0x78d1e13ceff0>]
Python 调试#
另一个由开发工作流程而非数值计算驱动的应用是,在反向模式自动微分的反向传播中设置 pdb 调试器跟踪。
在尝试追溯 nan 运行时错误的来源,或者只是仔细检查正在传播的余切(梯度)值时,在反向传播中插入一个与原计算中特定点对应的调试器会很有用。您可以使用 jax.custom_vjp 来实现。
我们将示例推迟到下一节。
迭代实现的隐式函数微分#
这个例子深入到了数学的细节!
jax.custom_vjp 的另一个应用是函数进行反向模式微分,这些函数虽然可进行 JAX 转换(通过 jit、vmap 等),但由于某种原因无法高效地进行 JAX 微分,可能是因为它们涉及到 lax.while_loop。(不可能生成一个高效计算 XLA HLO While 循环反向模式导数的 XLA HLO 程序,因为那需要一个具有无限内存使用的程序,而这在 XLA HLO 中是无法表达的,至少在没有通过入队/出队产生副作用交互的情况下是如此。)
例如,考虑这个 fixed_point 例程,它通过在 while_loop 中迭代应用函数来计算定点。
from jax.lax import while_loop
def fixed_point(f, a, x_guess):
def cond_fun(carry):
x_prev, x = carry
return jnp.abs(x_prev - x) > 1e-6
def body_fun(carry):
_, x = carry
return x, f(a, x)
_, x_star = while_loop(cond_fun, body_fun, (x_guess, f(a, x_guess)))
return x_star
这是一个数值求解方程 \(x = f(a, x)\) 的迭代过程,通过迭代 \(x_{t+1} = f(a, x_t)\) 直到 \(x_{t+1}\) 足够接近 \(x_t\)。结果 \(x^*\) 取决于参数 \(a\),因此我们可以认为存在一个函数 \(a \mapsto x^*(a)\),它由方程 \(x = f(a, x)\) 隐式定义。
我们可以使用 fixed_point 来运行迭代过程直至收敛,例如运行牛顿法来计算平方根,同时只执行加法、乘法和除法。
def newton_sqrt(a):
update = lambda a, x: 0.5 * (x + a / x)
return fixed_point(update, a, a)
print(newton_sqrt(2.))
1.4142135
我们也可以对函数进行 vmap 或 jit 转换。
print(jit(vmap(newton_sqrt))(jnp.array([1., 2., 3., 4.])))
[1. 1.4142135 1.7320509 2. ]
我们无法应用反向模式自动微分,因为存在 while_loop,但事实证明我们本来也不想这样做:与其对 fixed_point 的实现及其所有迭代进行微分,不如利用数学结构做一些更节省内存(且在这种情况下,更节省浮点运算)的事情!我们可以转而使用隐函数定理 [Bertsekas 的《非线性规划》第二版附录 A.25],它(在某些条件下)保证了我们即将使用的数学对象的存在。本质上,我们在解处进行线性化,并迭代求解这些线性方程以计算我们想要的导数。
再次考虑方程 \(x = f(a, x)\) 和函数 \(x^*\)。我们希望评估像 \(v^\mathsf{T} \mapsto v^\mathsf{T} \partial x^*(a_0)\) 这样的向量-雅可比积。
至少在我们要微分的点 \(a_0\) 周围的开邻域中,假设方程 \(x^*(a) = f(a, x^*(a))\) 对所有 \(a\) 都成立。由于等式两边作为 \(a\) 的函数是相等的,它们的导数也必须相等,所以我们对两边进行微分:
\(\qquad \partial x^*(a) = \partial_0 f(a, x^*(a)) + \partial_1 f(a, x^*(a)) \partial x^*(a)\).
设 \(A = \partial_1 f(a_0, x^*(a_0))\) 和 \(B = \partial_0 f(a_0, x^*(a_0))\),我们可以更简单地写出我们所求的量:
\(\qquad \partial x^*(a_0) = B + A \partial x^*(a_0)\),
或者,通过重新排列:
\(\qquad \partial x^*(a_0) = (I - A)^{-1} B\).
这意味着我们可以评估像这样的向量-雅可比积:
\(\qquad v^\mathsf{T} \partial x^*(a_0) = v^\mathsf{T} (I - A)^{-1} B = w^\mathsf{T} B\),
其中 \(w^\mathsf{T} = v^\mathsf{T} (I - A)^{-1}\),或者等价地 \(w^\mathsf{T} = v^\mathsf{T} + w^\mathsf{T} A\),或者等价地 \(w^\mathsf{T}\) 是映射 \(u^\mathsf{T} \mapsto v^\mathsf{T} + u^\mathsf{T} A\) 的定点。最后一个特性为我们提供了一种通过调用 fixed_point 来编写 fixed_point 的 VJP 的方法!此外,在展开 \(A\) 和 \(B\) 后,我们可以看到我们只需要在 \((a_0, x^*(a_0))\) 处评估 \(f\) 的 VJP。
结论如下:
from jax import vjp
@partial(custom_vjp, nondiff_argnums=(0,))
def fixed_point(f, a, x_guess):
def cond_fun(carry):
x_prev, x = carry
return jnp.abs(x_prev - x) > 1e-6
def body_fun(carry):
_, x = carry
return x, f(a, x)
_, x_star = while_loop(cond_fun, body_fun, (x_guess, f(a, x_guess)))
return x_star
def fixed_point_fwd(f, a, x_init):
x_star = fixed_point(f, a, x_init)
return x_star, (a, x_star)
def fixed_point_rev(f, res, x_star_bar):
a, x_star = res
_, vjp_a = vjp(lambda a: f(a, x_star), a)
a_bar, = vjp_a(fixed_point(partial(rev_iter, f),
(a, x_star, x_star_bar),
x_star_bar))
return a_bar, jnp.zeros_like(x_star)
def rev_iter(f, packed, u):
a, x_star, x_star_bar = packed
_, vjp_x = vjp(lambda x: f(a, x), x_star)
return x_star_bar + vjp_x(u)[0]
fixed_point.defvjp(fixed_point_fwd, fixed_point_rev)
print(newton_sqrt(2.))
1.4142135
print(grad(newton_sqrt)(2.))
print(grad(grad(newton_sqrt))(2.))
0.35355338
-0.088388346
我们可以通过对 jnp.sqrt 进行微分来检查我们的结果,它使用了完全不同的实现。
print(grad(jnp.sqrt)(2.))
print(grad(grad(jnp.sqrt))(2.))
0.35355338
-0.08838835
这种方法的局限性在于,参数 f 不能闭合任何涉及微分的值。也就是说,您可能会注意到我们将参数 a 在 fixed_point 的参数列表中明确列出。对于此用例,请考虑使用低级原语 lax.custom_root,它允许在闭合变量中使用自定义求根函数的导数。
jax.custom_jvp 和 jax.custom_vjp API 的基本用法#
使用 jax.custom_jvp 定义前向模式(以及间接的,反向模式)规则#
以下是使用 jax.custom_jvp 的一个典型基本示例,其中注释使用了Haskell 风格的类型签名。
from jax import custom_jvp
import jax.numpy as jnp
# f :: a -> b
@custom_jvp
def f(x):
return jnp.sin(x)
# f_jvp :: (a, T a) -> (b, T b)
def f_jvp(primals, tangents):
x, = primals
t, = tangents
return f(x), jnp.cos(x) * t
f.defjvp(f_jvp)
<function __main__.f_jvp(primals, tangents)>
from jax import jvp
print(f(3.))
y, y_dot = jvp(f, (3.,), (1.,))
print(y)
print(y_dot)
0.14112
0.14112
-0.9899925
换句话说,我们从一个原函数 f 开始,它接受类型 a 的输入并产生类型 b 的输出。我们为其关联一个 JVP 规则函数 f_jvp,该函数接受一对输入,分别表示类型 a 的原输入和相应的类型 T a 的切线输入,并产生一对输出,分别表示类型 b 的原输出和类型 T b 的切线输出。切线输出应该是切线输入的线性函数。
您也可以将 f.defjvp 用作装饰器,如下所示:
@custom_jvp
def f(x):
...
@f.defjvp
def f_jvp(primals, tangents):
...
尽管我们只定义了 JVP 规则而没有定义 VJP 规则,但我们可以在 f 上使用前向和反向模式微分。JAX 会自动转置来自我们自定义 JVP 规则的切线值上的线性计算,计算 VJP 的效率就如同我们手动编写该规则一样。
from jax import grad
print(grad(f)(3.))
print(grad(grad(f))(3.))
-0.9899925
-0.14112
为了使自动转置工作,JVP 规则的输出切线必须是输入切线的线性函数。否则会引发转置错误。
多个参数的工作方式如下:
@custom_jvp
def f(x, y):
return x ** 2 * y
@f.defjvp
def f_jvp(primals, tangents):
x, y = primals
x_dot, y_dot = tangents
primal_out = f(x, y)
tangent_out = 2 * x * y * x_dot + x ** 2 * y_dot
return primal_out, tangent_out
print(grad(f)(2., 3.))
12.0
defjvps 便利封装器允许我们分别为每个参数定义 JVP,然后分别计算结果并求和。
@custom_jvp
def f(x):
return jnp.sin(x)
f.defjvps(lambda t, ans, x: jnp.cos(x) * t)
print(grad(f)(3.))
-0.9899925
这是一个带有多个参数的 defjvps 示例。
@custom_jvp
def f(x, y):
return x ** 2 * y
f.defjvps(lambda x_dot, primal_out, x, y: 2 * x * y * x_dot,
lambda y_dot, primal_out, x, y: x ** 2 * y_dot)
print(grad(f)(2., 3.))
print(grad(f, 0)(2., 3.)) # same as above
print(grad(f, 1)(2., 3.))
12.0
12.0
4.0
作为一种简写方式,使用 defjvps 时,您可以传递 None 值来指示特定参数的 JVP 为零。
@custom_jvp
def f(x, y):
return x ** 2 * y
f.defjvps(lambda x_dot, primal_out, x, y: 2 * x * y * x_dot,
None)
print(grad(f)(2., 3.))
print(grad(f, 0)(2., 3.)) # same as above
print(grad(f, 1)(2., 3.))
12.0
12.0
0.0
使用关键字参数调用 jax.custom_jvp 函数,或编写带有默认参数的 jax.custom_jvp 函数定义,这两种方式都是允许的,只要它们能根据标准库 inspect.signature 机制检索到的函数签名明确地映射到位置参数即可。
当您不执行微分时,函数 f 的调用方式与未被 jax.custom_jvp 装饰时完全相同。
@custom_jvp
def f(x):
print('called f!') # a harmless side-effect
return jnp.sin(x)
@f.defjvp
def f_jvp(primals, tangents):
print('called f_jvp!') # a harmless side-effect
x, = primals
t, = tangents
return f(x), jnp.cos(x) * t
from jax import vmap, jit
print(f(3.))
called f!
0.14112
print(vmap(f)(jnp.arange(3.)))
print(jit(f)(3.))
called f!
[0. 0.84147096 0.9092974 ]
called f!
0.14112
自定义 JVP 规则在微分过程中被调用,无论是前向还是反向。
y, y_dot = jvp(f, (3.,), (1.,))
print(y_dot)
called f_jvp!
called f!
-0.9899925
print(grad(f)(3.))
called f_jvp!
called f!
-0.9899925
请注意,f_jvp 调用 f 来计算原输出。在高阶微分的上下文中,只有当规则调用原始 f 来计算原输出时,微分变换的每次应用才会使用自定义 JVP 规则。(这代表了一种基本的权衡,我们不能在规则中利用 f 求值产生的中间值,同时又让规则适用于所有高阶微分。)
grad(grad(f))(3.)
called f_jvp!
called f_jvp!
called f!
Array(-0.14112, dtype=float32, weak_type=True)
您可以将 Python 控制流与 jax.custom_jvp 一起使用。
@custom_jvp
def f(x):
if x > 0:
return jnp.sin(x)
else:
return jnp.cos(x)
@f.defjvp
def f_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = f(x)
if x > 0:
return ans, 2 * x_dot
else:
return ans, 3 * x_dot
print(grad(f)(1.))
print(grad(f)(-1.))
2.0
3.0
使用 jax.custom_vjp 定义自定义反向模式专用规则#
虽然 jax.custom_jvp 足以控制前向模式以及通过 JAX 自动转置实现的反向模式微分行为,但在某些情况下,我们可能希望直接控制 VJP 规则,例如在前面介绍的最后两个示例问题中。我们可以使用 jax.custom_vjp 来实现。
from jax import custom_vjp
import jax.numpy as jnp
# f :: a -> b
@custom_vjp
def f(x):
return jnp.sin(x)
# f_fwd :: a -> (b, c)
def f_fwd(x):
return f(x), jnp.cos(x)
# f_bwd :: (c, CT b) -> CT a
def f_bwd(cos_x, y_bar):
return (cos_x * y_bar,)
f.defvjp(f_fwd, f_bwd)
from jax import grad
print(f(3.))
print(grad(f)(3.))
0.14112
-0.9899925
换句话说,我们再次从一个原函数 f 开始,它接受类型 a 的输入并产生类型 b 的输出。我们为其关联两个函数:f_fwd 和 f_bwd,它们分别描述如何执行反向模式自动微分的前向和后向传播。
函数 f_fwd 描述前向传播,不仅包括原计算,还包括为后向传播保存哪些值。它的输入签名与原函数 f 相同,即它接受类型 a 的原输入。但作为输出,它产生一对值,其中第一个元素是原输出 b,第二个元素是任何类型 c 的“残差”数据,用于存储以供后向传播使用。(这个第二个输出类似于 PyTorch 的 save_for_backward 机制。)
函数 f_bwd 描述后向传播。它接受两个输入,第一个是 f_fwd 产生的类型 c 的残差数据,第二个是对应于原函数输出的类型 CT b 的输出余切。它产生类型 CT a 的输出,表示对应于原函数输入的余切。特别地,f_bwd 的输出必须是一个序列(例如元组),其长度等于原函数的参数数量。
因此,多个参数的工作方式如下:
from jax import custom_vjp
@custom_vjp
def f(x, y):
return jnp.sin(x) * y
def f_fwd(x, y):
return f(x, y), (jnp.cos(x), jnp.sin(x), y)
def f_bwd(res, g):
cos_x, sin_x, y = res
return (cos_x * g * y, sin_x * g)
f.defvjp(f_fwd, f_bwd)
print(grad(f)(2., 3.))
-1.2484405
使用关键字参数调用 jax.custom_vjp 函数,或编写带有默认参数的 jax.custom_vjp 函数定义,这两种方式都是允许的,只要它们能根据标准库 inspect.signature 机制检索到的函数签名明确地映射到位置参数即可。
与 jax.custom_jvp 一样,如果未应用微分,则由 f_fwd 和 f_bwd 组成的自定义 VJP 规则不会被调用。如果函数被求值,或通过 jit、vmap 或其他非微分转换进行转换,则只调用 f。
@custom_vjp
def f(x):
print("called f!")
return jnp.sin(x)
def f_fwd(x):
print("called f_fwd!")
return f(x), jnp.cos(x)
def f_bwd(cos_x, y_bar):
print("called f_bwd!")
return (cos_x * y_bar,)
f.defvjp(f_fwd, f_bwd)
print(f(3.))
called f!
0.14112
print(grad(f)(3.))
called f_fwd!
called f!
called f_bwd!
-0.9899925
y, f_vjp = vjp(f, 3.)
print(y)
called f_fwd!
called f!
0.14112
print(f_vjp(1.))
called f_bwd!
(Array(-0.9899925, dtype=float32, weak_type=True),)
前向模式自动微分不能用于 jax.custom_vjp 函数,否则会引发错误。
from jax import jvp
try:
jvp(f, (3.,), (1.,))
except TypeError as e:
print('ERROR! {}'.format(e))
called f_fwd!
called f!
ERROR! can't apply forward-mode autodiff (jvp) to a custom_vjp function.
如果您想同时使用前向和反向模式,请改用 jax.custom_jvp。
我们可以将 jax.custom_vjp 与 pdb 结合使用,在反向传播中插入调试器跟踪。
import pdb
@custom_vjp
def debug(x):
return x # acts like identity
def debug_fwd(x):
return x, x
def debug_bwd(x, g):
pdb.set_trace()
return g
debug.defvjp(debug_fwd, debug_bwd)
def foo(x):
y = x ** 2
y = debug(y) # insert pdb in corresponding backward pass step
return jnp.sin(y)
jax.grad(foo)(3.)
> <ipython-input-113-b19a2dc1abf7>(12)debug_bwd()
-> return g
(Pdb) p x
Array(9., dtype=float32)
(Pdb) p g
Array(-0.91113025, dtype=float32)
(Pdb) q
更多功能和细节#
使用 list / tuple / dict 容器(以及其他 Py树)#
您应该期望标准 Python 容器(如列表、元组、命名元组和字典)以及它们的嵌套版本能够正常工作。通常,只要它们的结构根据类型约束保持一致,任何Py树都是允许的。
以下是一个使用 jax.custom_jvp 的人为设计的示例。
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
@custom_jvp
def f(pt):
x, y = pt.x, pt.y
return {'a': x ** 2,
'b': (jnp.sin(x), jnp.cos(y))}
@f.defjvp
def f_jvp(primals, tangents):
pt, = primals
pt_dot, = tangents
ans = f(pt)
ans_dot = {'a': 2 * pt.x * pt_dot.x,
'b': (jnp.cos(pt.x) * pt_dot.x, -jnp.sin(pt.y) * pt_dot.y)}
return ans, ans_dot
def fun(pt):
dct = f(pt)
return dct['a'] + dct['b'][0]
pt = Point(1., 2.)
print(f(pt))
{'a': 1.0, 'b': (Array(0.84147096, dtype=float32, weak_type=True), Array(-0.41614684, dtype=float32, weak_type=True))}
print(grad(fun)(pt))
Point(x=Array(2.5403023, dtype=float32, weak_type=True), y=Array(0., dtype=float32, weak_type=True))
以及一个使用 jax.custom_vjp 的类似的人为设计的示例。
@custom_vjp
def f(pt):
x, y = pt.x, pt.y
return {'a': x ** 2,
'b': (jnp.sin(x), jnp.cos(y))}
def f_fwd(pt):
return f(pt), pt
def f_bwd(pt, g):
a_bar, (b0_bar, b1_bar) = g['a'], g['b']
x_bar = 2 * pt.x * a_bar + jnp.cos(pt.x) * b0_bar
y_bar = -jnp.sin(pt.y) * b1_bar
return (Point(x_bar, y_bar),)
f.defvjp(f_fwd, f_bwd)
def fun(pt):
dct = f(pt)
return dct['a'] + dct['b'][0]
pt = Point(1., 2.)
print(f(pt))
{'a': 1.0, 'b': (Array(0.84147096, dtype=float32, weak_type=True), Array(-0.41614684, dtype=float32, weak_type=True))}
print(grad(fun)(pt))
Point(x=Array(2.5403023, dtype=float32, weak_type=True), y=Array(-0., dtype=float32, weak_type=True))
处理不可微分参数#
某些用例,例如最后一个示例问题,需要将不可微分参数(例如函数值参数)传递给具有自定义微分规则的函数,并且这些参数也要传递给规则本身。在 fixed_point 的例子中,函数参数 f 就是这样一个不可微分参数。jax.experimental.odeint 也出现了类似的情况。
带有 nondiff_argnums 的 jax.custom_jvp#
使用 jax.custom_jvp 的可选参数 nondiff_argnums 来指示此类参数。以下是一个使用 jax.custom_jvp 的示例。
from functools import partial
@partial(custom_jvp, nondiff_argnums=(0,))
def app(f, x):
return f(x)
@app.defjvp
def app_jvp(f, primals, tangents):
x, = primals
x_dot, = tangents
return f(x), 2. * x_dot
print(app(lambda x: x ** 3, 3.))
27.0
print(grad(app, 1)(lambda x: x ** 3, 3.))
2.0
请注意这里的陷阱:无论这些参数在参数列表中的何处出现,它们都将放置在相应 JVP 规则签名的开头。这是另一个例子。
@partial(custom_jvp, nondiff_argnums=(0, 2))
def app2(f, x, g):
return f(g((x)))
@app2.defjvp
def app2_jvp(f, g, primals, tangents):
x, = primals
x_dot, = tangents
return f(g(x)), 3. * x_dot
print(app2(lambda x: x ** 3, 3., lambda y: 5 * y))
3375.0
print(grad(app2, 1)(lambda x: x ** 3, 3., lambda y: 5 * y))
3.0
带有 nondiff_argnums 的 jax.custom_vjp#
jax.custom_vjp 也存在类似选项,同样,约定是无论不可微分参数在原始函数签名中的何处出现,它们都作为 _bwd 规则的第一个参数传递。而 _fwd 规则的签名保持不变——它与原函数的签名相同。以下是一个示例。
@partial(custom_vjp, nondiff_argnums=(0,))
def app(f, x):
return f(x)
def app_fwd(f, x):
return f(x), x
def app_bwd(f, x, g):
return (5 * g,)
app.defvjp(app_fwd, app_bwd)
print(app(lambda x: x ** 2, 4.))
16.0
print(grad(app, 1)(lambda x: x ** 2, 4.))
5.0
有关另一个用法示例,请参阅上面的 fixed_point。
您不需要对数组值参数使用 nondiff_argnums,例如那些具有整数数据类型的参数。相反,nondiff_argnums 仅应用于不对应 JAX 类型(本质上不对应数组类型)的参数值,例如 Python 可调用对象或字符串。如果 JAX 检测到由 nondiff_argnums 指示的参数包含 JAX Tracer,则会引发错误。上面的 clip_gradient 函数是无需为整数数据类型数组参数使用 nondiff_argnums 的一个很好的例子。